CC1G_13852
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_13852 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | D6RKV4 | Functional description | Mannosyl-glycoprotein endo-beta-N-acetylglucosaminidase (EC 3.2.1.96) |
| Location | Chr_2:740179..742661 | Strand | + |
| Gene length (nt) | 2483 | Transcript length (nt) | 2070 |
| CDS length (nt) | 2070 | Protein length (aa) | 689 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Grifola frondosa | Grifr_OBZ65487 | 48.7 | 4.088E-151 | 497 |
| Auricularia subglabra | Aurde3_1_1413065 | 36.2 | 3.852E-101 | 350 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 11403 |
| Description | Mannosyl-glycoprotein endo-beta-N-acetylglucosaminidase (EC 3.2.1.96) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF03644 | Glycosyl hydrolase family 85 | IPR005201 | 86 | 415 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR005201 | Glycoside hydrolase, family 85 |
| IPR032979 | Cytosolic endo-beta-N-acetylglucosaminidase |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0005737 | cytoplasm | CC |
| GO:0033925 | mannosyl-glycoprotein endo-beta-N-acetylglucosaminidase activity | MF |
KEGG
| KEGG Orthology |
|---|
| K01227 |
EggNOG
| COG category | Description |
|---|---|
| G | Glycosyl hydrolase family 85 |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| GH | GH85 |
Transcription factor
| Group |
|---|
| No records |
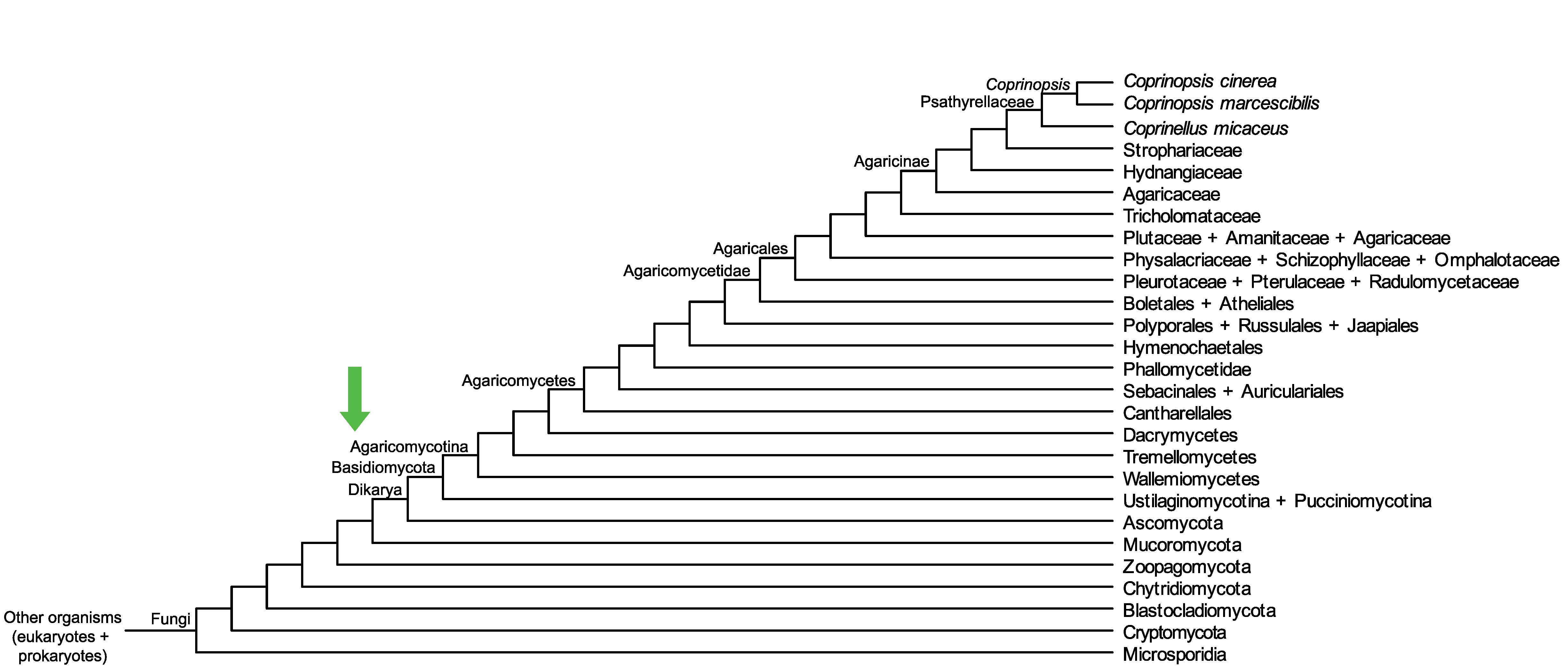
Conservation of CC1G_13852 across fungi.
Arrow shows the origin of gene family containing CC1G_13852.
Protein
| Sequence id | 11403 |
|---|---|
| Sequence |
>11403 MPVRGTVPQPRALPEYFQSFQELDDWRTSKTGPFYSAEGVRPYVPRRLRTEDITGQGRLLIAHDFKVNTNERRLC PSIAVLTGPGSFAHHRITIPPPEWIASAHRQGVPILGTLGLHVLKWNYGRMFEGEAQEDCFRMVIGTQPRNATVD DAPWSRANYTVPVSPHYAEILADIAKERGFDGWLINIEMDLKGGSSQARGIAAWVSLFQQEVLKKVGSHGLVLWY DSVTFRGHLSWQERLSSRNLPFFLSSSGLFTNYAWYNHFPQRQIDYFNSLDPKLLKGKSLQDIYAGIDMWGRGSH GGGGFGMYKALEHADPQKLGLSIALLAPGWTWESENENPGWTWERFWEQDTNLWVGPSSSKVAIEVPPTEFKVVE PMCEHGPFKPVSKFFPTLPPPDPLDLAFYTSFSPGVGHQWFVEGKEVFYSGSGWTDIEKQTSTGDLVWPKPTVYN LVGGGLSDADASSALYFEDAWNGGNSLQINVTRTRGSTGYAGYWVPIQSLSLSTGNRYEASVVYKVGEGATGDVD AKLDLGVRGGGTRRNAGFKLLEEDTTALASGWAKARIVFEPSAAEGEESIVPASIGFIVSVSSDSTKSSPSNNSF LLPFLVGQIAVHPHLPADYHSFEASLYSLSFKRNATSRSPLDGMLSWDIVAALPEPPEPDESPDRDDPNLFWEVQ PTERNWFPKPRTDG |
| Length | 689 |
Coding
| Sequence id | CC1G_13852T0 |
|---|---|
| Sequence |
>CC1G_13852T0 ATGCCAGTCCGCGGAACGGTACCCCAACCTAGAGCTCTTCCCGAATATTTCCAATCGTTCCAGGAGCTAGATGAC TGGAGAACGAGCAAGACAGGGCCGTTCTATTCTGCGGAGGGTGTTCGACCTTATGTTCCGAGGAGGTTGAGGACT GAGGATATTACTGGGCAAGGGAGGCTACTGATCGCGCATGACTTCAAGGTGAATACCAACGAACGACGTCTATGT CCCAGCATCGCCGTTCTGACTGGCCCAGGGAGCTTCGCACACCACCGGATAACCATTCCTCCACCAGAATGGATT GCCTCGGCACATAGACAGGGAGTCCCAATACTAGGAACACTAGGACTTCATGTACTCAAATGGAACTACGGCAGG ATGTTCGAAGGAGAAGCCCAGGAAGACTGCTTTCGCATGGTAATAGGAACGCAACCCCGCAACGCCACAGTGGAC GACGCACCATGGTCGAGGGCCAATTACACCGTCCCAGTCTCCCCGCACTACGCGGAAATCCTCGCAGACATTGCC AAAGAACGCGGATTCGACGGTTGGCTAATTAACATAGAAATGGATTTGAAGGGAGGGTCTTCGCAAGCTCGTGGA ATAGCCGCTTGGGTATCTCTATTTCAGCAAGAGGTTTTGAAGAAGGTCGGGAGCCATGGCTTAGTGCTTTGGTAC GACAGTGTCACGTTCAGAGGCCATCTTTCCTGGCAAGAGCGACTATCCTCTCGCAACCTGCCCTTCTTCCTCAGC TCGAGTGGGTTGTTCACCAACTACGCGTGGTACAACCATTTCCCCCAGCGCCAGATTGACTACTTCAATAGCCTC GACCCGAAACTCCTCAAGGGTAAATCCCTCCAAGACATTTACGCAGGTATCGACATGTGGGGACGAGGCTCGCAC GGCGGCGGCGGATTCGGAATGTACAAAGCCCTCGAGCACGCCGACCCTCAAAAGCTCGGACTCAGCATCGCACTC TTAGCTCCAGGCTGGACATGGGAATCCGAAAACGAAAACCCGGGCTGGACATGGGAGCGTTTCTGGGAACAAGAC ACGAATTTATGGGTCGGACCGTCCTCGAGTAAAGTGGCTATCGAAGTCCCGCCAACCGAGTTCAAGGTTGTCGAA CCGATGTGTGAGCATGGGCCGTTTAAACCTGTGTCCAAATTCTTCCCGACTCTCCCCCCTCCGGATCCCCTGGAT TTGGCATTTTATACGTCATTTTCGCCGGGCGTTGGGCATCAGTGGTTTGTAGAGGGGAAGGAAGTCTTTTATTCA GGGTCTGGGTGGACGGATATCGAGAAGCAAACAAGTACGGGGGATTTGGTGTGGCCGAAGCCTACAGTGTATAAC TTGGTGGGAGGAGGGCTGAGCGACGCGGATGCAAGCTCAGCGCTTTATTTCGAAGACGCTTGGAATGGCGGGAAC TCGTTGCAGATTAATGTTACCCGCACTAGGGGCTCGACGGGGTATGCAGGGTATTGGGTACCCATTCAGTCGCTT AGCCTGTCGACGGGGAACCGCTATGAAGCCTCGGTGGTCTACAAAGTAGGAGAAGGGGCAACTGGGGATGTGGAT GCGAAGCTGGATTTGGGAGTGAGAGGTGGTGGTACTAGGAGAAACGCAGGATTCAAGCTCTTGGAGGAGGATACG ACTGCTTTGGCTTCTGGATGGGCGAAGGCTCGGATTGTCTTCGAGCCATCTGCTGCTGAAGGCGAGGAAAGCATC GTGCCAGCGTCCATCGGCTTCATCGTATCCGTGTCCAGCGACTCCACGAAGTCCAGCCCAAGCAACAACTCATTC CTTCTCCCCTTCCTCGTCGGCCAGATTGCTGTACATCCACACCTCCCAGCCGACTACCATTCCTTCGAAGCATCG CTTTACTCGCTCAGCTTTAAACGCAACGCGACCTCTCGCAGTCCACTGGATGGCATGTTATCTTGGGATATCGTC GCAGCGCTCCCCGAACCTCCCGAACCAGACGAGTCTCCAGATCGAGATGACCCTAACCTTTTCTGGGAAGTTCAA CCCACCGAGAGGAATTGGTTCCCCAAACCAAGAACGGATGGA |
| Length | 2070 |
Transcript
| Sequence id | CC1G_13852T0 |
|---|---|
| Sequence |
>CC1G_13852T0 ATGCCAGTCCGCGGAACGGTACCCCAACCTAGAGCTCTTCCCGAATATTTCCAATCGTTCCAGGAGCTAGATGAC TGGAGAACGAGCAAGACAGGGCCGTTCTATTCTGCGGAGGGTGTTCGACCTTATGTTCCGAGGAGGTTGAGGACT GAGGATATTACTGGGCAAGGGAGGCTACTGATCGCGCATGACTTCAAGGTGAATACCAACGAACGACGTCTATGT CCCAGCATCGCCGTTCTGACTGGCCCAGGGAGCTTCGCACACCACCGGATAACCATTCCTCCACCAGAATGGATT GCCTCGGCACATAGACAGGGAGTCCCAATACTAGGAACACTAGGACTTCATGTACTCAAATGGAACTACGGCAGG ATGTTCGAAGGAGAAGCCCAGGAAGACTGCTTTCGCATGGTAATAGGAACGCAACCCCGCAACGCCACAGTGGAC GACGCACCATGGTCGAGGGCCAATTACACCGTCCCAGTCTCCCCGCACTACGCGGAAATCCTCGCAGACATTGCC AAAGAACGCGGATTCGACGGTTGGCTAATTAACATAGAAATGGATTTGAAGGGAGGGTCTTCGCAAGCTCGTGGA ATAGCCGCTTGGGTATCTCTATTTCAGCAAGAGGTTTTGAAGAAGGTCGGGAGCCATGGCTTAGTGCTTTGGTAC GACAGTGTCACGTTCAGAGGCCATCTTTCCTGGCAAGAGCGACTATCCTCTCGCAACCTGCCCTTCTTCCTCAGC TCGAGTGGGTTGTTCACCAACTACGCGTGGTACAACCATTTCCCCCAGCGCCAGATTGACTACTTCAATAGCCTC GACCCGAAACTCCTCAAGGGTAAATCCCTCCAAGACATTTACGCAGGTATCGACATGTGGGGACGAGGCTCGCAC GGCGGCGGCGGATTCGGAATGTACAAAGCCCTCGAGCACGCCGACCCTCAAAAGCTCGGACTCAGCATCGCACTC TTAGCTCCAGGCTGGACATGGGAATCCGAAAACGAAAACCCGGGCTGGACATGGGAGCGTTTCTGGGAACAAGAC ACGAATTTATGGGTCGGACCGTCCTCGAGTAAAGTGGCTATCGAAGTCCCGCCAACCGAGTTCAAGGTTGTCGAA CCGATGTGTGAGCATGGGCCGTTTAAACCTGTGTCCAAATTCTTCCCGACTCTCCCCCCTCCGGATCCCCTGGAT TTGGCATTTTATACGTCATTTTCGCCGGGCGTTGGGCATCAGTGGTTTGTAGAGGGGAAGGAAGTCTTTTATTCA GGGTCTGGGTGGACGGATATCGAGAAGCAAACAAGTACGGGGGATTTGGTGTGGCCGAAGCCTACAGTGTATAAC TTGGTGGGAGGAGGGCTGAGCGACGCGGATGCAAGCTCAGCGCTTTATTTCGAAGACGCTTGGAATGGCGGGAAC TCGTTGCAGATTAATGTTACCCGCACTAGGGGCTCGACGGGGTATGCAGGGTATTGGGTACCCATTCAGTCGCTT AGCCTGTCGACGGGGAACCGCTATGAAGCCTCGGTGGTCTACAAAGTAGGAGAAGGGGCAACTGGGGATGTGGAT GCGAAGCTGGATTTGGGAGTGAGAGGTGGTGGTACTAGGAGAAACGCAGGATTCAAGCTCTTGGAGGAGGATACG ACTGCTTTGGCTTCTGGATGGGCGAAGGCTCGGATTGTCTTCGAGCCATCTGCTGCTGAAGGCGAGGAAAGCATC GTGCCAGCGTCCATCGGCTTCATCGTATCCGTGTCCAGCGACTCCACGAAGTCCAGCCCAAGCAACAACTCATTC CTTCTCCCCTTCCTCGTCGGCCAGATTGCTGTACATCCACACCTCCCAGCCGACTACCATTCCTTCGAAGCATCG CTTTACTCGCTCAGCTTTAAACGCAACGCGACCTCTCGCAGTCCACTGGATGGCATGTTATCTTGGGATATCGTC GCAGCGCTCCCCGAACCTCCCGAACCAGACGAGTCTCCAGATCGAGATGACCCTAACCTTTTCTGGGAAGTTCAA CCCACCGAGAGGAATTGGTTCCCCAAACCAAGAACGGATGGATAA |
| Length | 2070 |
Gene
| Sequence id | CC1G_13852T0 |
|---|---|
| Sequence |
>CC1G_13852T0 ATGCCAGTCCGCGGAACGGTACCCCAACCTAGAGCTCTTCCCGAATATTTCCAATCGTTCCAGGAGCTAGATGAC TGGAGAACGAGCAAGACAGGGCCGTTCTATTCTGCGGAGGGTGTTCGACCTTATGTTCCGAGGAGGTTGAGGACT GAGGATATTACTGGGCAAGGGAGGCTACTGGTGAGTACACGAACCATAATCACTCCAGGCCATCTTTTGAGTTCG GTTCTTCTTCTAGATCGCGCATGACTTCAAGGTGAATACCAACGAACGACGTCTATGTCCCAGCATCGCCGTTCT GACTGGCCCAGGGAGGTTATATTGAAGACCCATTCACAAAATCATATACTTTCAATTGGTGGTCATCTACCTCCC TATTCAATTAGTCGGTCTTCCTTTCGAACCCGTTCCCCCCAATTGCGTTAACACCCCCGTTTATAGCTTCGCACA CCACCGGATAACCATTCCTCCACCAGAATGGATTGCCTCGGCACATAGACAGGGAGTCCCAATACTAGGAACACT GTGAGCAACCTCTCTTTCGAGAGGACTTCATGTACTCAAATGGAACTACGGCAGGATGTTCGAAGGAGAAGCCCA GGAAGACTGCTTTCGCATGGTAATAGGAACGCAACCCCGCAACGCCACAGTGGACGACGCACCATGGTCGAGGGC CAATTACACCGTCCCAGTCTCCCCGCACTACGCGGAAATCCTCGCAGACATTGCCAAAGAACGCGGATTCGACGG TTGGCTAATTAACATAGAAATGGATTTGAAGGGAGGGTCTTCGCAAGCTCGTGGAATAGCCGCTTGGGTATCTCT ATTTCAGCAAGAGGTTTTGAAGAAGGTCGGGAGCCATGGCTTAGTGCTTTGGTACGACAGTGTCACGTTCAGAGG CCATCTTTCCTGGCAAGAGCGACTATCCTCTCGCAACCTGCCCTTCTTCCTCAGCTCGAGTGGGTTGTTCACCAA CTACGCGGTGCGTTCTCTTCTGTCTTCGGAAACTAGAATAGCCGAGCTGATACATGTACAGTGGTACAACCATTT CCCCCAGCGCCAGATTGACTACTTCAATAGCCTCGACCCGAAACTCCTCAAGGGTAAATCCCTCCAAGACATTTA CGCAGGTATCGACATGTGGGGACGAGGCTCGCACGGCGGCGGCGGATTCGGAATGTACAAAGCCCTCGAGCACGC CGACCCTCAAAAGCTCGGACTCAGCATCGCACTCTTAGCTCCAGGCTGGACATGGGAATCCGAAAACGAAAACCC GGGCTGGACATGGGAGCGTTTCTGGGAACAAGACACGAATTTATGGGTCGGACCGTCCTCGAGTAAAGTGGCTAT CGAAGTCCCGCCAACCGAGTTCAAGGTTGTCGAACCGATGTGTGAGCATGGGCCGTTTAAACCTGTGTCCAAATT CTTCCCGACTCTCCCCCCTCCGGATCCCCTGGATTTGGCATTTTATACGTCATTTTCGCCGGGCGTTGGGCATCA GTGGTTTGTAGAGGGGAAGGAAGTCTTTTATTCAGGGTCTGGGTGGACGGATATCGAGAAGCAAACAAGTACGGG GGATTTGGTGTGGCCGAAGCCTACAGTGTATAACTTGGTGGGAGGAGGGCTGAGCGACGCGGATGCAAGCTCAGC GCTTTATTTCGAAGACGCTTGGAATGGCGGGAACTCGTTGCAGATTAATGTTACCCGCACTAGGGGCTCGACGGG GTATGCAGGGTATTGGGTACCCATTCAGTCGCTTAGCCTGTCGACGGGGAACCGCTATGAAGCCTCGGTGGTCTA CAAAGTAGGAGAAGGGGCAACTGGGGATGTGGATGCGAAGCTGGATTTGGGAGTGAGAGGTGGTGGTACTAGGAG AAACGCAGGATTCAAGCTCTTGGAGGAGGATACGACTGCTTTGGCTTCTGGATGGGCGAAGGCTCGGATTGTCTT CGAGCCATCTGCTGCTGAAGGCGAGGAAAGCATCGTGCCAGCGTCCATCGGCTTCATCGTATCCGTGTCCAGCGA CTCCACGAAGTCCAGCCCAAGCAACAACTCATTCCTTCTCCCCTTCCTCGTCGGCCAGATTGCTGTACATCCACA CCTCCCAGCCGACTACCATTCCTTCGAAGCATCGCTTTACTCGCTCAGCTTTAAACGCAACGCGACCTCTCGCAG TCCACTGGATGGCATGTTATCTTGGGATATCGTCGCAGCGCTCCCCGAACCTCCCGAACCAGACGAGTCTCCAGA TCGAGATGACCCTAACCTTTTCTGGGAAGTTCAACCCACCGAGAGGAATTGGTTCCCCAAGTTCCTATACTTCAA TATCTACGCATCTGAAATCGCCGACGGAAACACCAGCCCATCGAAGGAGAACCAGAAATTCTGGATAGGCACCAC AGGATTCGACGGTGAAACCCGCAAATTCCACGTCTACGACCAGAACCTTCCACCCAGTTTGCAGACCAAGAACGG ATGGATAA |
| Length | 2483 |