CC1G_13961
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_13961 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | D6RKH6 | Functional description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
| Location | Chr_2:2277277..2282084 | Strand | + |
| Gene length (nt) | 4808 | Transcript length (nt) | 3627 |
| CDS length (nt) | 3627 | Protein length (aa) | 1208 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB23999 | 40.7 | 1.235E-280 | 895 |
| Agrocybe aegerita | Agrae_CAA7267623 | 40 | 9.673E-270 | 863 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1446698 | 36 | 3.574E-229 | 744 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1073822 | 35.3 | 4.955E-218 | 711 |
| Pleurotus ostreatus PC9 | PleosPC9_1_91922 | 35.3 | 4.85E-218 | 711 |
| Flammulina velutipes | Flave_chr10AA00103 | 52.4 | 1.273E-57 | 220 |
| Auricularia subglabra | Aurde3_1_1279061 | 28.7 | 6.194E-55 | 212 |
| Schizophyllum commune H4-8 | Schco3_2606711 | 30.5 | 3.573E-54 | 209 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 11512 |
| Description | Non-specific serine/threonine protein kinase (EC 2.7.11.1) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd21037 | MLKL_NTD | - | 17 | 148 |
| CDD | cd06224 | REM | IPR000651 | 818 | 924 |
| Pfam | PF07714 | Protein tyrosine and serine/threonine kinase | IPR001245 | 228 | 481 |
| Pfam | PF00618 | RasGEF N-terminal motif | IPR000651 | 814 | 892 |
| Pfam | PF00617 | RasGEF domain | IPR001895 | 970 | 1047 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR036537 | Adaptor protein Cbl, N-terminal domain superfamily |
| IPR001245 | Serine-threonine/tyrosine-protein kinase, catalytic domain |
| IPR008266 | Tyrosine-protein kinase, active site |
| IPR001895 | Ras guanine-nucleotide exchange factors catalytic domain |
| IPR000651 | Ras-like guanine nucleotide exchange factor, N-terminal |
| IPR000719 | Protein kinase domain |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR023578 | Ras guanine nucleotide exchange factor domain superfamily |
| IPR036964 | Ras guanine-nucleotide exchange factor, catalytic domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0007166 | cell surface receptor signaling pathway | BP |
| GO:0004672 | protein kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0005085 | guanyl-nucleotide exchange factor activity | MF |
| GO:0007264 | small GTPase mediated signal transduction | BP |
| GO:0005524 | ATP binding | MF |
KEGG
| KEGG Orthology |
|---|
| K03099 |
| K04365 |
| K06619 |
EggNOG
| COG category | Description |
|---|---|
| T | kinase-like protein |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
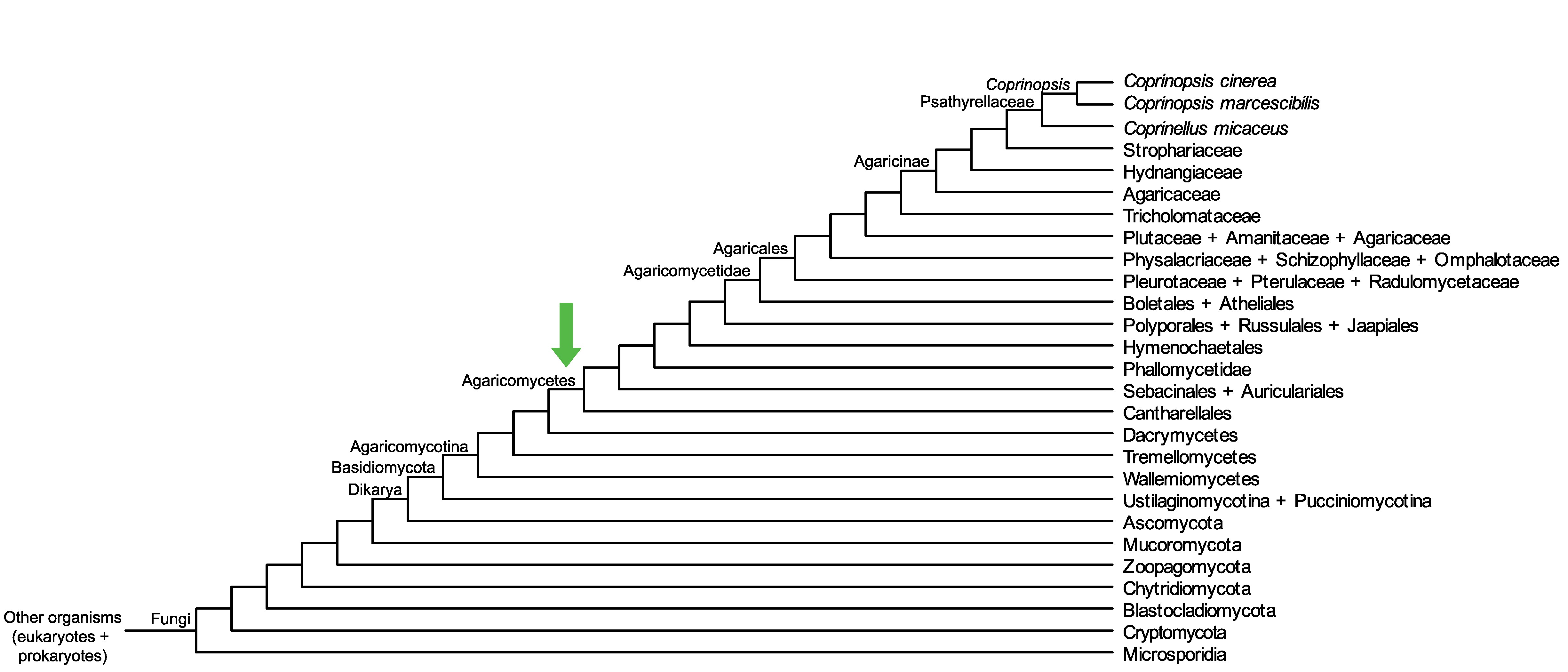
Conservation of CC1G_13961 across fungi.
Arrow shows the origin of gene family containing CC1G_13961.
Protein
| Sequence id | 11512 |
|---|---|
| Sequence |
>11512 MSLKDLLVLSPVPGLDAAVTILTATWNNVQNVKVYKQQCHDLSTRCTMLILALNEGMQNQHQSNDWATELENVVR AINAKVQEWARLNRLKSFLQQSEIQEALHRFHRRLDGAMDRYHIAATLEFRRGLYESRAILERDKAEMRTVLQQI ARDNSDLRSLLSETSGKPLEEIMEHFQTELMDPEIPKPQKDDFRFGLWWLHSRSSKLPPLPDLTGQVTKESEHVA FFGTFNDIYKGRWLNEKMVALRLPRSLPNTPRLQRRFEEEVKIWRKLNHPNVLTLYGITKIGQYVYLVSPWMDNG TAINYIQKNPNVDRLGLLEQITSGLEYLHSQNIVHGDIRGANILISENGVALLADFGLSKFLGDIGTVAQAMTVT VASNPRWSAPEILRNAGSKSTVSPYSKKSDIWSIGMTFLELLTGECPYAYESIDVAVLRLIDNNETPKRPREGKY HHNITDHLWKLMTRCWKMKPDSRPDIAYVRGKLIRIREEAYSPDAAQQSTQAASLFSPSFISTRVGTSRHQRVAT VDNYSVVSSNSGNDRNRPQDLPTLDVPQNGNLSHRPPSLRPSTSGSSNSGNSSNSGGPSKHRPNAPRFSPIDEDT ALSPTSYSSSPPSISPLSAFSAQALTGRSPAKRQGTGFSGFSGTNANKHPAPPSPSASISSSIDGNYRREFSSAP RLPPVSPPSSAGLLSELGWSKSSSSNSASSSRTVTQGTAYTRMDLRQSNGTRSNGNSGQNILYENNEETTPHRAT PSSSPPNANHPCTAPLPMKGKARSIDTVGVKSIFSTNSSVQPSDELQTAISSPEPIVYTNADRVTAGTLQGLVER LINNFNLQKDMEFRDVMLTACIDFITPEDMFNILIRRFEDAEQGSDMRPELRLGIQYTIFKVLMYWLLGRHLPVN TALLWRMEEFCQSAIKLKTSQPMIMKGNELLQLIEERIAEQRLEESRSSPFDLSPDRRVLSSSQITPRDLAIALT LLEGDKFRKIQPCDYLAHQRRQPISGYLNHVKAAAIVNTRIVQWVKQSILHFDEVRHRADVIKFYINTARNLLSE KFKKWLNEIVSILYPMDDYAAYRSALREIHDPQYADYCIPWLELHLDQLALLLRENSRVVEIDHHPLINFKRYLE YVKQFKSVLGFTPADLEEYRDQGQLAYLEHQLAGIEVTDSADDEMMKRSLELEQGETKLYEHRVLERQSLGFATP RKYRTSGK |
| Length | 1208 |
Coding
| Sequence id | CC1G_13961T0 |
|---|---|
| Sequence |
>CC1G_13961T0 ATGAGCCTGAAGGACCTGCTAGTCCTAAGTCCGGTACCTGGTCTCGATGCTGCTGTAACCATCTTAACCGCTACA TGGAACAACGTTCAGAACGTGAAGGTCTACAAGCAACAATGCCACGACCTGAGCACACGTTGCACGATGCTCATT CTAGCCCTCAACGAGGGGATGCAGAATCAGCATCAATCCAACGATTGGGCCACGGAACTCGAGAATGTTGTCCGC GCGATCAACGCCAAAGTGCAAGAATGGGCCAGGTTGAACCGCCTCAAATCGTTCCTCCAACAGAGCGAAATTCAA GAAGCCCTCCACCGTTTCCACCGACGTCTCGACGGTGCAATGGACAGGTATCATATAGCCGCTACTTTAGAATTT CGAAGGGGGTTGTACGAATCCCGAGCTATTCTGGAGCGAGACAAGGCCGAGATGCGTACAGTCCTGCAGCAGATC GCGAGGGATAACTCGGACCTCAGGTCACTCTTAAGCGAGACCTCCGGCAAACCTCTCGAGGAAATCATGGAGCAC TTCCAGACAGAACTCATGGACCCTGAAATCCCCAAACCACAGAAAGACGACTTTCGTTTTGGGCTGTGGTGGCTA CACTCGCGTTCGTCCAAACTGCCTCCCTTGCCAGATCTCACTGGTCAAGTCACCAAGGAGAGCGAGCATGTTGCG TTCTTCGGGACCTTCAACGATATTTATAAGGGACGGTGGTTGAACGAGAAGATGGTCGCACTCCGTTTACCAAGG AGTCTACCCAACACACCACGTCTACAACGGCGATTTGAAGAAGAAGTGAAGATATGGCGCAAGCTTAACCATCCC AACGTGCTCACGCTGTACGGCATCACGAAGATAGGACAGTACGTCTACCTGGTGAGCCCGTGGATGGACAATGGG ACCGCCATCAACTATATCCAGAAGAACCCCAACGTCGATCGACTTGGACTGTTGGAACAGATTACCTCAGGCCTC GAGTATCTCCACTCTCAGAACATTGTTCACGGCGACATTCGAGGGGCCAATATCCTGATATCCGAGAACGGCGTC GCTCTGTTAGCTGACTTTGGGCTATCAAAGTTCTTGGGGGATATCGGAACTGTCGCTCAAGCGATGACAGTAACC GTTGCGTCCAACCCTCGCTGGTCAGCTCCAGAAATCCTCCGCAATGCAGGCTCGAAATCCACGGTCTCACCATAT TCTAAGAAATCCGACATCTGGTCCATTGGGATGACCTTCCTCGAACTTCTGACGGGGGAATGCCCATATGCGTAT GAATCCATTGACGTCGCCGTACTTAGGCTCATCGACAACAACGAGACGCCAAAGCGGCCCCGGGAAGGGAAATAC CACCACAACATTACGGACCACTTGTGGAAGCTCATGACTCGATGCTGGAAGATGAAACCAGACTCTCGCCCCGAT ATCGCTTACGTTAGGGGCAAGCTGATACGAATACGGGAGGAAGCCTATTCTCCAGACGCTGCTCAACAGTCCACG CAGGCGGCGAGTCTATTCTCCCCTTCCTTCATCTCCACCAGAGTAGGCACATCGAGACACCAACGCGTGGCCACG GTTGATAACTATAGCGTCGTCAGCAGCAACAGTGGCAACGACAGGAACAGGCCGCAGGATCTACCTACGCTCGAC GTCCCACAGAATGGAAATCTATCGCACCGCCCACCAAGTTTGCGCCCGTCAACAAGCGGGAGTAGCAACAGCGGT AACTCCAGTAACTCAGGCGGGCCCAGCAAACACCGACCAAATGCCCCCAGGTTCTCTCCAATTGATGAGGACACT GCCCTCTCCCCAACCTCGTACTCCTCCAGCCCTCCATCGATATCCCCGCTGTCAGCCTTCTCCGCTCAAGCTCTC ACCGGTCGTAGCCCTGCCAAACGACAGGGTACAGGCTTTTCCGGTTTCTCGGGCACGAATGCGAACAAGCATCCA GCTCCGCCGTCGCCGAGCGCATCCATAAGTAGCAGCATTGACGGAAACTACCGTCGAGAGTTCTCCAGCGCTCCT CGCCTACCCCCCGTGTCCCCGCCTTCATCTGCTGGGTTGCTGTCCGAGTTGGGTTGGAGCAAGTCGTCATCGAGC AATTCTGCCAGCAGTAGCCGGACGGTCACTCAAGGAACAGCGTACACGCGCATGGACTTGCGGCAATCCAATGGA ACCCGATCCAACGGGAACAGTGGGCAAAACATACTATACGAGAATAATGAAGAGACAACCCCCCACCGCGCCACC CCTTCCTCCTCGCCCCCCAACGCGAACCATCCGTGTACTGCCCCGCTACCCATGAAAGGCAAGGCCCGTTCCATT GACACTGTGGGCGTGAAAAGCATATTTTCCACCAACTCCAGTGTCCAACCGTCAGACGAGCTTCAAACCGCCATC TCAAGCCCGGAACCGATCGTTTACACCAATGCGGACAGGGTCACAGCTGGTACTTTACAAGGGCTTGTCGAGAGG CTTATCAACAACTTCAATCTCCAGAAAGATATGGAGTTTCGCGATGTGATGCTTACAGCGTGTATCGACTTCATC ACCCCGGAGGATATGTTTAATATTCTGATCCGCCGCTTCGAGGATGCCGAGCAAGGGTCGGACATGAGGCCTGAA TTACGATTGGGTATCCAATATACGATCTTCAAGGTGCTTATGTACTGGTTGTTGGGCCGACATCTCCCCGTGAAC ACCGCCCTCCTCTGGCGAATGGAAGAATTCTGTCAATCGGCGATCAAGCTCAAGACCTCGCAGCCCATGATCATG AAGGGCAACGAGTTGCTCCAACTCATCGAAGAACGGATAGCGGAACAAAGACTTGAGGAATCTCGGAGCTCGCCA TTCGACTTGTCTCCCGATCGCAGAGTGTTGTCATCCTCCCAAATTACACCACGGGATCTCGCCATCGCCCTCACT CTCCTCGAGGGTGACAAGTTCCGCAAGATACAGCCATGCGACTATCTCGCCCACCAACGACGCCAACCAATTAGC GGTTATCTCAACCACGTCAAAGCCGCCGCCATCGTTAACACGCGTATCGTCCAATGGGTGAAGCAGTCGATCCTT CACTTTGACGAAGTCAGACACCGAGCAGACGTCATCAAGTTCTACATTAACACCGCGAGGAATCTACTCTCCGAG AAGTTCAAGAAGTGGTTGAATGAGATTGTGTCAATTCTCTATCCAATGGACGATTACGCAGCCTATCGCTCAGCA TTGCGTGAAATCCATGATCCTCAATACGCCGACTATTGCATCCCATGGCTAGAACTGCATCTCGACCAACTAGCC CTACTCCTCCGCGAGAACAGCCGAGTGGTCGAAATCGACCATCACCCGCTGATCAACTTCAAACGCTACCTCGAA TACGTCAAGCAATTCAAATCAGTCCTTGGATTCACACCCGCAGATCTAGAAGAGTACAGAGATCAGGGACAGCTT GCCTATCTCGAGCATCAGCTCGCTGGAATCGAGGTCACTGATTCGGCGGATGACGAGATGATGAAGAGGAGTTTG GAGTTGGAACAGGGGGAGACGAAGCTTTATGAACATCGCGTTTTGGAGCGGCAGAGTTTGGGCTTCGCCACGCCC AGAAAGTATCGGACGTCAGGCAAG |
| Length | 3627 |
Transcript
| Sequence id | CC1G_13961T0 |
|---|---|
| Sequence |
>CC1G_13961T0 ATGAGCCTGAAGGACCTGCTAGTCCTAAGTCCGGTACCTGGTCTCGATGCTGCTGTAACCATCTTAACCGCTACA TGGAACAACGTTCAGAACGTGAAGGTCTACAAGCAACAATGCCACGACCTGAGCACACGTTGCACGATGCTCATT CTAGCCCTCAACGAGGGGATGCAGAATCAGCATCAATCCAACGATTGGGCCACGGAACTCGAGAATGTTGTCCGC GCGATCAACGCCAAAGTGCAAGAATGGGCCAGGTTGAACCGCCTCAAATCGTTCCTCCAACAGAGCGAAATTCAA GAAGCCCTCCACCGTTTCCACCGACGTCTCGACGGTGCAATGGACAGGTATCATATAGCCGCTACTTTAGAATTT CGAAGGGGGTTGTACGAATCCCGAGCTATTCTGGAGCGAGACAAGGCCGAGATGCGTACAGTCCTGCAGCAGATC GCGAGGGATAACTCGGACCTCAGGTCACTCTTAAGCGAGACCTCCGGCAAACCTCTCGAGGAAATCATGGAGCAC TTCCAGACAGAACTCATGGACCCTGAAATCCCCAAACCACAGAAAGACGACTTTCGTTTTGGGCTGTGGTGGCTA CACTCGCGTTCGTCCAAACTGCCTCCCTTGCCAGATCTCACTGGTCAAGTCACCAAGGAGAGCGAGCATGTTGCG TTCTTCGGGACCTTCAACGATATTTATAAGGGACGGTGGTTGAACGAGAAGATGGTCGCACTCCGTTTACCAAGG AGTCTACCCAACACACCACGTCTACAACGGCGATTTGAAGAAGAAGTGAAGATATGGCGCAAGCTTAACCATCCC AACGTGCTCACGCTGTACGGCATCACGAAGATAGGACAGTACGTCTACCTGGTGAGCCCGTGGATGGACAATGGG ACCGCCATCAACTATATCCAGAAGAACCCCAACGTCGATCGACTTGGACTGTTGGAACAGATTACCTCAGGCCTC GAGTATCTCCACTCTCAGAACATTGTTCACGGCGACATTCGAGGGGCCAATATCCTGATATCCGAGAACGGCGTC GCTCTGTTAGCTGACTTTGGGCTATCAAAGTTCTTGGGGGATATCGGAACTGTCGCTCAAGCGATGACAGTAACC GTTGCGTCCAACCCTCGCTGGTCAGCTCCAGAAATCCTCCGCAATGCAGGCTCGAAATCCACGGTCTCACCATAT TCTAAGAAATCCGACATCTGGTCCATTGGGATGACCTTCCTCGAACTTCTGACGGGGGAATGCCCATATGCGTAT GAATCCATTGACGTCGCCGTACTTAGGCTCATCGACAACAACGAGACGCCAAAGCGGCCCCGGGAAGGGAAATAC CACCACAACATTACGGACCACTTGTGGAAGCTCATGACTCGATGCTGGAAGATGAAACCAGACTCTCGCCCCGAT ATCGCTTACGTTAGGGGCAAGCTGATACGAATACGGGAGGAAGCCTATTCTCCAGACGCTGCTCAACAGTCCACG CAGGCGGCGAGTCTATTCTCCCCTTCCTTCATCTCCACCAGAGTAGGCACATCGAGACACCAACGCGTGGCCACG GTTGATAACTATAGCGTCGTCAGCAGCAACAGTGGCAACGACAGGAACAGGCCGCAGGATCTACCTACGCTCGAC GTCCCACAGAATGGAAATCTATCGCACCGCCCACCAAGTTTGCGCCCGTCAACAAGCGGGAGTAGCAACAGCGGT AACTCCAGTAACTCAGGCGGGCCCAGCAAACACCGACCAAATGCCCCCAGGTTCTCTCCAATTGATGAGGACACT GCCCTCTCCCCAACCTCGTACTCCTCCAGCCCTCCATCGATATCCCCGCTGTCAGCCTTCTCCGCTCAAGCTCTC ACCGGTCGTAGCCCTGCCAAACGACAGGGTACAGGCTTTTCCGGTTTCTCGGGCACGAATGCGAACAAGCATCCA GCTCCGCCGTCGCCGAGCGCATCCATAAGTAGCAGCATTGACGGAAACTACCGTCGAGAGTTCTCCAGCGCTCCT CGCCTACCCCCCGTGTCCCCGCCTTCATCTGCTGGGTTGCTGTCCGAGTTGGGTTGGAGCAAGTCGTCATCGAGC AATTCTGCCAGCAGTAGCCGGACGGTCACTCAAGGAACAGCGTACACGCGCATGGACTTGCGGCAATCCAATGGA ACCCGATCCAACGGGAACAGTGGGCAAAACATACTATACGAGAATAATGAAGAGACAACCCCCCACCGCGCCACC CCTTCCTCCTCGCCCCCCAACGCGAACCATCCGTGTACTGCCCCGCTACCCATGAAAGGCAAGGCCCGTTCCATT GACACTGTGGGCGTGAAAAGCATATTTTCCACCAACTCCAGTGTCCAACCGTCAGACGAGCTTCAAACCGCCATC TCAAGCCCGGAACCGATCGTTTACACCAATGCGGACAGGGTCACAGCTGGTACTTTACAAGGGCTTGTCGAGAGG CTTATCAACAACTTCAATCTCCAGAAAGATATGGAGTTTCGCGATGTGATGCTTACAGCGTGTATCGACTTCATC ACCCCGGAGGATATGTTTAATATTCTGATCCGCCGCTTCGAGGATGCCGAGCAAGGGTCGGACATGAGGCCTGAA TTACGATTGGGTATCCAATATACGATCTTCAAGGTGCTTATGTACTGGTTGTTGGGCCGACATCTCCCCGTGAAC ACCGCCCTCCTCTGGCGAATGGAAGAATTCTGTCAATCGGCGATCAAGCTCAAGACCTCGCAGCCCATGATCATG AAGGGCAACGAGTTGCTCCAACTCATCGAAGAACGGATAGCGGAACAAAGACTTGAGGAATCTCGGAGCTCGCCA TTCGACTTGTCTCCCGATCGCAGAGTGTTGTCATCCTCCCAAATTACACCACGGGATCTCGCCATCGCCCTCACT CTCCTCGAGGGTGACAAGTTCCGCAAGATACAGCCATGCGACTATCTCGCCCACCAACGACGCCAACCAATTAGC GGTTATCTCAACCACGTCAAAGCCGCCGCCATCGTTAACACGCGTATCGTCCAATGGGTGAAGCAGTCGATCCTT CACTTTGACGAAGTCAGACACCGAGCAGACGTCATCAAGTTCTACATTAACACCGCGAGGAATCTACTCTCCGAG AAGTTCAAGAAGTGGTTGAATGAGATTGTGTCAATTCTCTATCCAATGGACGATTACGCAGCCTATCGCTCAGCA TTGCGTGAAATCCATGATCCTCAATACGCCGACTATTGCATCCCATGGCTAGAACTGCATCTCGACCAACTAGCC CTACTCCTCCGCGAGAACAGCCGAGTGGTCGAAATCGACCATCACCCGCTGATCAACTTCAAACGCTACCTCGAA TACGTCAAGCAATTCAAATCAGTCCTTGGATTCACACCCGCAGATCTAGAAGAGTACAGAGATCAGGGACAGCTT GCCTATCTCGAGCATCAGCTCGCTGGAATCGAGGTCACTGATTCGGCGGATGACGAGATGATGAAGAGGAGTTTG GAGTTGGAACAGGGGGAGACGAAGCTTTATGAACATCGCGTTTTGGAGCGGCAGAGTTTGGGCTTCGCCACGCCC AGAAAGTATCGGACGTCAGGCAAGTAA |
| Length | 3627 |
Gene
| Sequence id | CC1G_13961T0 |
|---|---|
| Sequence |
>CC1G_13961T0 ATGAGCCTGAAGGACCTGCTAGTCCTAAGTCCGGTACCTGGTCTCGATGCTGCTGTAACCATCTGTGAGTGCACT CATTTCCTTTTGTTCATAGCCCGAGCAGTGCTTACTCGCCTTGTGTTGCCAATGCAGTAACCGCTACATGGAACA ACGTTCAGAACGTGAAGGTCTACAAGGTAGGTTATCGTATCCTCTCCTCCATCCGCGTCGCTCATGGCGCGACAC AGCAACAATGCCACGACCTGAGCACACGTTGCACGATGCTCATTCTAGCCCTCAACGAGGGGATGCAGAATCAGC ATCAATCCAACGATTGGGCCACGGAACTCGAGAAGTGAGTAAAGCGAGATAACCATCTTCAGTAGCCTCTTCGCT TCGAGAACTCAACTCTTCCTCCGCGCTTTCTAGTGTTGTCCGCGCGATCAACGCCAAAGTGCAAGAATGGGCCAG GTTGAACCGCCTCAAATCGTTCCTCCAACAGAGCGAAATTCAAGAAGCCCTCCACCGTTTCCACCGACGTCTCGA CGGTGCAATGGACAGGTATCATGTAAGTGACGACCCATTGCATTCAGCGTTTTGTTGACCGGGCGAGCTTTCATC TACAGATAGCCGCTACTTTAGAATTTCGAAGGGGGTTGTACGAATCCCGAGCTATTCTGGAGCGAGACAAGGCCG AGATGCGTACAGTCCTGCAGCAGATCGCGAGGGATAACTCGGACCTCAGGTCACTCTTAAGCGAGACCTCCGGCA AACCTCTCGAGGAAATCATGGAGCACTTCCAGACAGTGAGTTCCATCTGCCCGTTGTCAGTACGGATGACCAAAT ACAATGTTTTGCCCATGTTTAGGAACTCATGGACCCTGAAATCCCCAAACCACAGAAAGACGACTTTCGTTTTGG GCTGTGGTGGCTACACTCGCGTTCGTCCAAACTGCCTCCCTTGCCAGATCGTAAGCCTTCCCGCTTTTAGTACTA CGAAAGCTGTTCAAACAAAACCATCGCCTCCTCGATATAGTCACTGGTCAAGTCACCAAGGAGAGCGAGCATGTT GCGTTCTTCGGGACCTTCAACGATATTTATAAGGGTACGCAGAATATCCTTGCCTTACAATGAAGGACACAAAAA GTTGATCCGTGTTTGGCACCAAGGACGGTGGTTGAACGAGAAGATGGTAAGGATCTATTTGGCGCCTTTATTTTT AGAACATCTGAGCCAATTCCATTGTGCCACTCTAGGTCGCACTCCGTTTACCAAGGAGTCTACCCAACACACCAC GTCTACAACGGGTTAGTGTTCCTGGAAGCAGGCGCGTTCAACGTATTAATTAATTTATCGCAGCGATTTGAAGAA GAAGTGAAGATATGGCGCAAGCTTAACCATCCCAACGTGCTCACGCTGTACGGCATCACGAAGATAGGACAGTAC GTCTACCTGGTGAGCCCGTGGATGGACAATGGGACCGCCATCAACTATATCCAGAAGAACCCCAACGTCGATCGA CTTGGACTGTTGGAACAGATTACCTCAGGTTGGCATCCCCTCCACCTTTCCATGAAAGAAACTCAATAACCCTTG CGCCAGGCCTCGAGTATCTCCACTCTCAGAACATTGTTCACGGCGACATTCGAGGGGTAAGTATGGTACCCCTAT CAACTCATACCCCATTCTAATGGCAAGCACCACTGCATAGGCCAATATCCTGATATCCGAGAACGGCGTCGCTCT GTTAGCTGACTTTGGGCTATCAAAGTTCTTGGGGGATATCGGAACTGTACGCATCCCGCCTCTTTCCTGTCGACT ATCTGACTCAATGCTATCAGGTCGCTCAAGCGATGACAGTAACCGTTGCGTCCAACCCTCGCTGGTCAGCTCCAG AAATCCTCCGCAATGCAGGCTCGAAATCCACGGTCTCACCATATTCTAAGAAATCCGACATCTGGTCCATTGGGA TGACCTTCCTCGAACTTCTGACGGGGGAATGCCCATATGCGTATGAATCCATTGACGTCGCCGTACTTAGGCTCA TCGACAACAACGAGACGCCAAAGCGGCCCCGGGAAGGGAAATACCACCACAACATTACGGACCACTTGTGGAAGC TCATGACTCGATGCTGGAAGATGAAACCAGACTCTCGCCCCGATATCGCTTACGTTAGGGGCAAGCTGATACGAA TACGGGAGGAAGCCTATTCTCCAGGTATGGTTTTATCCCCATGTTGATTCCGAGTGCCGCATCCTTACTCCTTTC AGACGCTGCTCAACAGTCCACGCAGGCGGCGAGTCTATTCTCCCCTTCCTTCATCTCCACCAGAGTAGGCACATC GAGACACCAACGCGTGGCCACGGTTGATAACTATAGCGTCGTCAGCAGCAACAGTGGCAACGACAGGAACAGGCC GCAGGATCTACCTACGCTCGACGTCCCACAGAATGGAAATCTATCGCACCGCCCACCAAGTTTGCGCCCGTCAAC AAGCGGGAGTAGCAACAGCGGTAACTCCAGTAACTCAGGCGGGCCCAGCAAACACCGACCAAATGCCCCCAGGTT CTCTCCAATTGATGAGGACACTGCCCTCTCCCCAACCTCGTACTCCTCCAGCCCTCCATCGATATCCCCGCTGTC AGCCTTCTCCGCTCAAGCTCTCACCGGTCGTAGCCCTGCCAAACGACAGGGTACAGGCTTTTCCGGTTTCTCGGG CACGAATGCGAACAAGCATCCAGCTCCGCCGTCGCCGAGCGCATCCATAAGTAGCAGCATTGACGGAAACTACCG TCGAGAGTTCTCCAGCGCTCCTCGCCTACCCCCCGTGTCCCCGCCTTCATCTGCTGGGTTGCTGTCCGAGTTGGG TTGGAGCAAGTCGTCATCGAGCAATTCTGCCAGCAGTAGCCGGACGGTCACTCAAGGAACAGCGTACACGCGCAT GGACTTGCGGCAATCCAATGGAACCCGATCCAACGGGAACAGTGGGCAAAACATACTATACGAGAATAATGAAGA GACAACCCCCCACCGCGCCACCCCTTCCTCCTCGCCCCCCAACGCGAACCATCCGTGTACTGCCCCGCTACCCAT GAAAGGCAAGGCCCGTTCCATTGACACTGTGGGCGTGAAAAGCATATTTTCCACCAACTCCAGTGTCCAACCGTC AGACGAGCTTCAAACCGCCATCTCAAGCCCGGAACCGATCGTTTACACCAATGCGGACAGGGTCACAGCTGGTAC TTTACAAGGGCTTGTCGAGAGGCTTATCAACAACTTCAGTAAGCAAATTCCCTCCCAACTGTCGCACCATCTTCG ATTCTAATCACGCCTTTCCATTCTCCTAGATCTCCAGAAAGATATGGAGTTTCGCGATGTGATGCTTACAGCGTG TATCGACTTCATCACCCCGGAGGATATGTTTAATATTCTGATCCGCCGCTTCGAGGATGCCGAGCAAGGGTCGGA CATGAGGCCTGAATTACGATTGGGTATCCAATATACGTGAGTTAGCCTGGTTTCCTTCCGGAAAGGAGGTTCTAA CATCTTTATCGCCAGGATCTTCAAGGTGCTTATGTACTGGTTGTTGGGCCGACATCTCCCCGTGAACACCGCCCT CCTCTGGCGAATGGAAGAATTCTGTCAATCGGCGATCAAGCTCAAGACCTCGCAGCCCATGATCATGAAGGGCAA CGAGTTGCTCCAACTCATCGAAGAACGGGTAAGGATAACCCCGATATTCACCTCTACGGCTAACATCTCATGATA TGTAGATAGCGGAACAAAGACTTGAGGAATCTCGGAGCTCGCCATTCGACTTGTCTCCCGATCGCAGAGTGTTGT CATCCTCCCAAATTACACCACGGGATCTCGCCATCGCCCTCACTCTCCTCGAGGGTGACAAGTTCCGCAAGATAC AGCCATGCGACTATCTCGCCCACCAACGACGCCAACCAATTAGCGGTTATCTCAACCACGTCAAAGCCGCCGCCA TCGTTAACACGCGTATCGTCCAATGGGTGAAGCAGTCGATCCTTCACTTTGACGAAGTCAGACACCGAGCAGACG TCATCAAGTTCTACATTAACACCGCGAGGGTGAGTGGCTACGGAACTTTCCATTGAACTGTTGACGAAATCATCC TTCTTTGCCTCTTCTTGAATATACAGGAATGCCGCAAGTTGCGCAATTACAGTTCCTTTGTTGCCATTGCGATGG GGCTAGATTCAAAGCCAGTGGAGCGGCTGAAACTCACAAAGAATCTACTCTCCGAGAAGTTCAAGAAGTGGTTGA ATGAGATTGTGTCAATTCTCTATCCAATGGACGATTACGCAGCCTATCGCTCAGCATTGCGTGAAATCCATGATC CTCAATACGCCGACTATTGCATCCCATGGCTAGGTGAGAAAGAGTTATCTCCCTTTCCCCGAAATACATCCCGAT AACTGTTTTTTTTTCCCGCCACACAACCTCTAGAACTGCATCTCGACCAACTAGCCCTACTCCTCCGCGAGAACA GCCGAGTGGTCGAAATCGACCATCACCCGCTGATCAACTTCAAACGCTACCTCGAATACGTCAAGCAATTCAAAT CAGTCCTTGGATTCACACCCGCAGATCTAGAAGAGTACAGAGATCAGGGACAGCTTGCCTATCTCGAGCATCAGC TCGCTGGAATCGAGGTCACTGATTCGGCGGATGACGAGATGATGAAGAGGAGTTTGGAGTTGGAACAGGGGGAGA CGAAGCTTTATGAACATCGCGTTTTGGAGCGGCAGAGTTTGGGCTTCGCCACGCCCAGAAAGTATCGGACGTCAG GCAAGTAA |
| Length | 4808 |