CC1G_14245
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_14245 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | D6RLQ2 | Functional description | CMGC/DYRK/YAK protein kinase |
| Location | Chr_3:2545782..2550144 | Strand | + |
| Gene length (nt) | 4363 | Transcript length (nt) | 3456 |
| CDS length (nt) | 3198 | Protein length (aa) | 1065 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| Neurospora crassa | prk-2 |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Agrocybe aegerita | Agrae_CAA7261724 | 66.9 | 0 | 1624 |
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB24920 | 64.6 | 0 | 1603 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1379755 | 70.6 | 0 | 1301 |
| Grifola frondosa | Grifr_OBZ67161 | 56.1 | 0 | 1292 |
| Lentinula edodes NBRC 111202 | Lenedo1_1171265 | 53.7 | 0 | 1249 |
| Schizophyllum commune H4-8 | Schco3_2739833 | 68.1 | 0 | 1246 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_16427 | 53 | 0 | 1238 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_18410 | 69.8 | 0 | 1024 |
| Auricularia subglabra | Aurde3_1_1159901 | 55 | 5.716E-291 | 925 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_69717 | 86 | 1.216E-265 | 850 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_36909 | 86 | 1.267E-265 | 850 |
| Pleurotus ostreatus PC15 | PleosPC15_2_28329 | 86.5 | 1.492E-264 | 847 |
| Pleurotus ostreatus PC9 | PleosPC9_1_37574 | 86.5 | 1.461E-264 | 847 |
| Lentinula edodes B17 | Lened_B_1_1_2628 | 50.1 | 2.782E-171 | 572 |
| Flammulina velutipes | Flave_chr07AA00594 | 47.8 | 1.67E-106 | 376 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 11796 |
| Description | CMGC/DYRK/YAK protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 340 | 603 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR000719 | Protein kinase domain |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR017441 | Protein kinase, ATP binding site |
| IPR011009 | Protein kinase-like domain superfamily |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
KEGG
| KEGG Orthology |
|---|
| K18670 |
EggNOG
| COG category | Description |
|---|---|
| T | Serine/Threonine protein kinases, catalytic domain |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
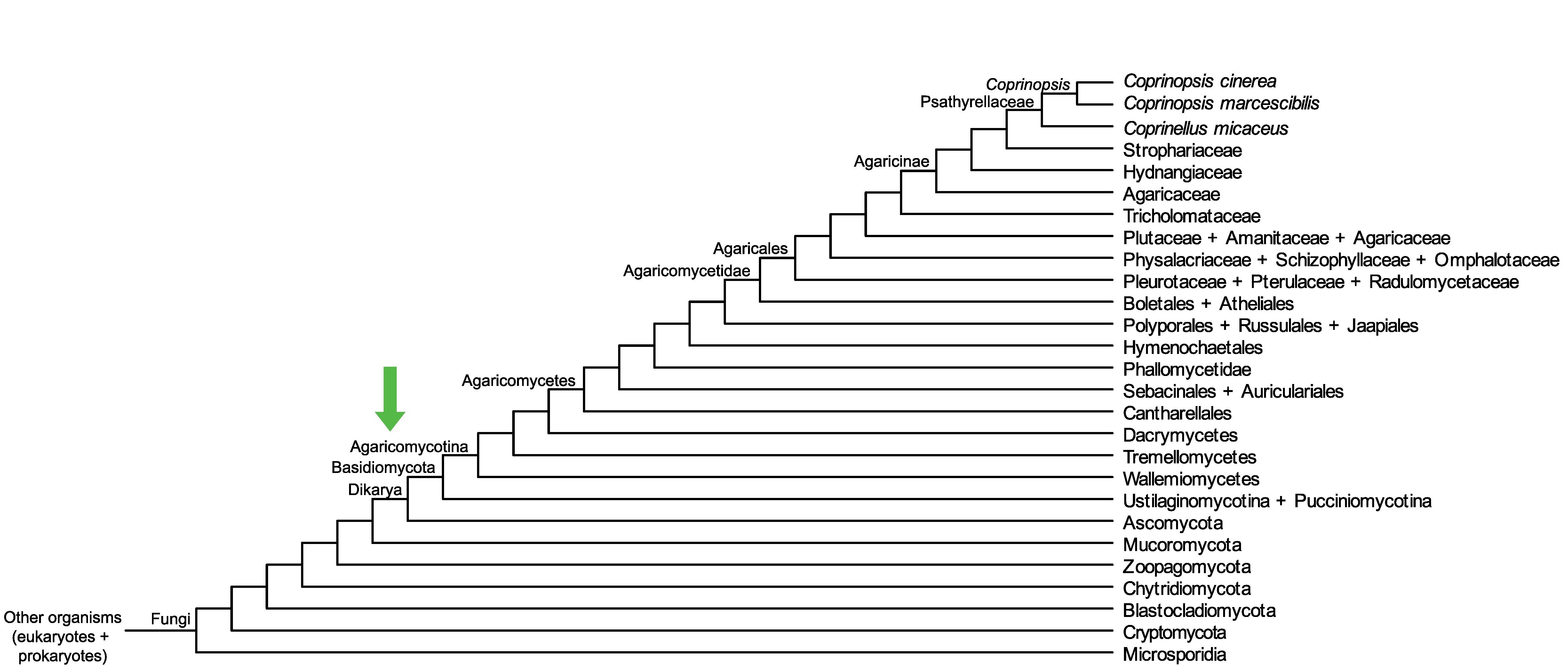
Conservation of CC1G_14245 across fungi.
Arrow shows the origin of gene family containing CC1G_14245.
Protein
| Sequence id | 11796 |
|---|---|
| Sequence |
>11796 MQDSNESSFDLPRWQTHVEPAAQATPYLYGPPPPSQHSMSGSSPQRIQPVHQSHTGSSTRQPRISQLLEQEHSLS PPSNQYTPSNQAPLSRSASLGGTSASNLASRLVRRHNQPDDLEAYNTDNQGLSGPRQQPQLSQNTFYNPSVGYQS PSMTGNVSSGTTAGSTSDSYSDLYYNGSASQPPKRIQDPNRAAGRSPHRAANPTNSTGLIDAYAQQQSQYSPTTA TYSYGPGPPQSTGYQTHGRSNSQVKQEQATPPIASPYAPQNQSHQPLRQLTTNIVETYRICNPSYRYESAHNPRR VLTKPSKPVHNEGYDNEDYDYILYVNDWLGTEEGHKYLILDILGQGTFGQVVKCQNMKTHEIVAVKVIKNKPAYF NQSMMEVTILEMLNKTCDPNDEHHLLRLRDSFIHRSHLCLVFELLSSNLYELIKQNQFQGLSTQLVKVFMAQLLD ALTVLKEARLIHCDLKPENILLKSLQSPQIKVIDFGSACHERQTVYTYIQSRFYRSPEVLLGMPYTAAIDMWSLG CIAVELFLGLPLFPGTSEYNQLTRIIEMLGMPPLSMLNSGKQTKLNNRAAFIDFCKGLLDLNPVTRWTPQQARLH PFITGEKFTKPFVPEGLAPSQPSSSSSPNTPDPKRPYGGLVPSQPKGTRAYQDAATYNHHLAQHQAYTAQQASQA ANTFRNPYINPPAQQQQSQQQHQQQPPSQPPVAQTTYTNPPADPYHPQSQQQQSQSQHLSGQYGSGAAQTAHRAL AHANSANQLGSGASGSQYPSHSSATNLSSSHLNPNVSSGSYYPNSRARANTINQMDTIPPALARLQHMNQDIIGG RNALTPVLNRDDAMKEWERRQSGKPPAAQPYPQLEYLQQQAEIVAASGLANWASGPHTRYPAQPSKLQHSYQPHT IMVDDENGNTSRRDVVMSNVRAAAGGGARTDQQSGLGSYSGSTGNLITSPPQAYSGNTAAGSRYTTSYGQPQHPP PPASSNSFDTVDRRTDIGMYVPMQPDQYQGYPASTSTNRHAPPAGPPVPTSFYGPSIVPSGSQQQRNPFNVQENA QQSMGQPKDNRNWPR |
| Length | 1065 |
Coding
| Sequence id | CC1G_14245T0 |
|---|---|
| Sequence |
>CC1G_14245T0 ATGCAAGACTCTAACGAATCGTCGTTCGACCTTCCTCGTTGGCAGACCCATGTCGAGCCTGCAGCCCAGGCAACT CCCTACCTTTATGGCCCACCGCCGCCTTCACAGCATTCCATGTCCGGATCGTCACCCCAACGCATCCAGCCAGTC CACCAGAGCCACACAGGTTCTTCAACCAGGCAGCCACGAATTTCTCAGTTGCTCGAGCAGGAACACTCATTAAGC CCGCCATCCAACCAGTATACACCCTCAAACCAGGCCCCATTGTCCCGCAGTGCATCCCTTGGAGGTACCAGCGCA AGTAACCTGGCTTCGCGCCTTGTCAGGCGCCATAATCAACCGGACGATTTGGAAGCCTACAATACTGACAACCAA GGACTATCGGGACCCCGTCAGCAACCCCAACTCTCCCAAAACACGTTTTACAACCCCAGTGTTGGGTATCAGTCA CCATCGATGACAGGGAACGTTTCATCTGGCACGACAGCAGGCTCAACATCCGATTCCTACTCAGATCTCTACTAC AATGGTTCAGCCAGTCAACCACCAAAGAGAATCCAAGATCCCAACCGTGCCGCCGGTCGATCGCCACACCGAGCC GCCAATCCTACCAATTCAACGGGACTCATAGACGCTTACGCTCAACAGCAATCGCAATACTCTCCGACAACAGCA ACGTACTCGTACGGTCCTGGTCCCCCACAATCGACTGGTTATCAGACCCACGGTCGCAGCAACTCCCAGGTCAAG CAAGAGCAAGCGACACCCCCTATAGCAAGCCCTTATGCACCCCAGAATCAGTCCCACCAACCTTTGCGGCAACTC ACTACAAACATCGTCGAGACATACCGGATTTGCAACCCCAGCTATCGCTATGAATCGGCTCATAACCCCAGACGG GTTCTCACCAAGCCGAGCAAACCCGTTCACAATGAAGGGTACGACAACGAGGATTATGATTACATTCTCTACGTC AATGATTGGCTGGGTACTGAAGAGGGCCACAAATACCTTATCCTTGATATTCTCGGTCAAGGAACGTTCGGCCAG GTGGTGAAATGCCAGAACATGAAGACACACGAGATTGTCGCCGTGAAAGTGATCAAGAACAAGCCCGCGTACTTT AACCAGAGTATGATGGAGGTCACGATCCTAGAGATGCTTAACAAAACCTGCGATCCAAACGACGAACACCACCTT CTTCGACTTCGCGATTCATTCATCCATCGAAGTCACCTGTGCCTCGTCTTTGAGCTTCTGTCGTCCAACCTTTAC GAGTTGATCAAGCAGAATCAATTCCAGGGTCTGAGTACGCAACTTGTCAAGGTCTTCATGGCCCAGCTTCTCGAC GCCTTGACCGTATTGAAAGAGGCACGGTTGATACACTGCGATTTGAAGCCTGAAAACATCCTATTGAAATCCCTT CAATCTCCTCAAATCAAAGTTATCGACTTCGGTTCTGCGTGTCATGAACGGCAAACAGTCTACACCTACATTCAG TCGCGATTCTATCGCTCACCTGAAGTCCTTTTGGGAATGCCTTACACGGCAGCTATCGACATGTGGTCATTGGGC TGCATTGCCGTCGAGCTATTCCTTGGTCTACCTCTTTTCCCTGGTACCAGCGAGTACAACCAGCTAACGAGGATA ATTGAGATGCTAGGGATGCCTCCTTTGAGCATGCTCAATAGCGGCAAGCAAACCAAACTCAATAACCGTGCTGCG TTCATCGACTTCTGCAAAGGCCTCTTGGATCTGAACCCTGTGACACGATGGACTCCACAGCAAGCGCGACTCCAC CCATTCATCACCGGAGAAAAGTTTACAAAACCCTTCGTCCCCGAAGGTCTGGCACCTTCACAACCCTCTTCTTCT TCGTCCCCGAACACCCCCGATCCCAAGCGTCCATACGGCGGTCTCGTTCCGTCTCAGCCGAAGGGCACGCGGGCT TATCAGGACGCGGCCACTTACAACCATCATCTCGCTCAGCACCAGGCATATACCGCCCAGCAGGCGTCGCAGGCT GCGAACACTTTCCGAAACCCGTACATCAATCCACCGGCTCAGCAACAGCAATCGCAGCAACAACATCAACAACAG CCACCATCCCAACCCCCTGTAGCACAAACGACCTATACAAACCCTCCTGCGGACCCGTACCACCCTCAGTCGCAA CAGCAACAGTCTCAGTCACAGCATCTCTCCGGCCAGTATGGAAGTGGAGCGGCACAAACTGCTCACCGTGCCCTT GCACACGCGAACTCTGCGAATCAATTGGGTTCTGGAGCATCTGGGTCACAATATCCCTCCCATTCGTCCGCCACA AACCTCTCGTCTTCGCATCTAAACCCGAATGTGTCGTCTGGTTCTTACTACCCCAATTCTCGCGCTCGGGCCAAC ACGATCAACCAGATGGATACCATTCCACCTGCTCTCGCTCGACTGCAACACATGAACCAAGACATAATCGGTGGA CGAAATGCATTGACGCCGGTCTTGAACCGTGATGACGCCATGAAAGAATGGGAGCGACGCCAATCTGGCAAACCT CCTGCTGCTCAACCGTACCCGCAATTGGAGTACCTGCAGCAGCAGGCGGAGATCGTAGCTGCGTCTGGCTTGGCC AACTGGGCGAGTGGTCCTCATACAAGGTACCCGGCGCAACCGTCAAAGTTGCAACACTCGTACCAACCTCATACG ATTATGGTTGACGATGAGAACGGGAATACCTCTAGGAGGGATGTGGTGATGTCCAATGTTCGCGCAGCTGCTGGT GGTGGTGCACGAACCGACCAGCAATCGGGGCTTGGCTCATACAGCGGGAGCACTGGAAACCTCATTACGAGTCCA CCACAAGCTTACTCCGGTAACACCGCGGCAGGAAGTCGGTACACGACAAGCTATGGGCAACCACAGCACCCGCCA CCGCCAGCATCTTCCAACTCGTTCGACACGGTAGATCGGCGGACGGATATCGGGATGTACGTGCCTATGCAGCCG GATCAGTACCAAGGCTATCCTGCTTCGACTTCGACGAACAGGCACGCTCCTCCGGCTGGACCGCCGGTTCCGACA TCGTTCTACGGACCTTCGATCGTTCCTTCAGGATCCCAACAACAGAGGAACCCGTTCAACGTGCAGGAGAACGCG CAGCAGTCTATGGGTCAACCTAAGGACAACCGCAACTGGCCCCGA |
| Length | 3198 |
Transcript
| Sequence id | CC1G_14245T0 |
|---|---|
| Sequence |
>CC1G_14245T0 ATGCAAGACTCTAACGAATCGTCGTTCGACCTTCCTCGTTGGCAGACCCATGTCGAGCCTGCAGCCCAGGCAACT CCCTACCTTTATGGCCCACCGCCGCCTTCACAGCATTCCATGTCCGGATCGTCACCCCAACGCATCCAGCCAGTC CACCAGAGCCACACAGGTTCTTCAACCAGGCAGCCACGAATTTCTCAGTTGCTCGAGCAGGAACACTCATTAAGC CCGCCATCCAACCAGTATACACCCTCAAACCAGGCCCCATTGTCCCGCAGTGCATCCCTTGGAGGTACCAGCGCA AGTAACCTGGCTTCGCGCCTTGTCAGGCGCCATAATCAACCGGACGATTTGGAAGCCTACAATACTGACAACCAA GGACTATCGGGACCCCGTCAGCAACCCCAACTCTCCCAAAACACGTTTTACAACCCCAGTGTTGGGTATCAGTCA CCATCGATGACAGGGAACGTTTCATCTGGCACGACAGCAGGCTCAACATCCGATTCCTACTCAGATCTCTACTAC AATGGTTCAGCCAGTCAACCACCAAAGAGAATCCAAGATCCCAACCGTGCCGCCGGTCGATCGCCACACCGAGCC GCCAATCCTACCAATTCAACGGGACTCATAGACGCTTACGCTCAACAGCAATCGCAATACTCTCCGACAACAGCA ACGTACTCGTACGGTCCTGGTCCCCCACAATCGACTGGTTATCAGACCCACGGTCGCAGCAACTCCCAGGTCAAG CAAGAGCAAGCGACACCCCCTATAGCAAGCCCTTATGCACCCCAGAATCAGTCCCACCAACCTTTGCGGCAACTC ACTACAAACATCGTCGAGACATACCGGATTTGCAACCCCAGCTATCGCTATGAATCGGCTCATAACCCCAGACGG GTTCTCACCAAGCCGAGCAAACCCGTTCACAATGAAGGGTACGACAACGAGGATTATGATTACATTCTCTACGTC AATGATTGGCTGGGTACTGAAGAGGGCCACAAATACCTTATCCTTGATATTCTCGGTCAAGGAACGTTCGGCCAG GTGGTGAAATGCCAGAACATGAAGACACACGAGATTGTCGCCGTGAAAGTGATCAAGAACAAGCCCGCGTACTTT AACCAGAGTATGATGGAGGTCACGATCCTAGAGATGCTTAACAAAACCTGCGATCCAAACGACGAACACCACCTT CTTCGACTTCGCGATTCATTCATCCATCGAAGTCACCTGTGCCTCGTCTTTGAGCTTCTGTCGTCCAACCTTTAC GAGTTGATCAAGCAGAATCAATTCCAGGGTCTGAGTACGCAACTTGTCAAGGTCTTCATGGCCCAGCTTCTCGAC GCCTTGACCGTATTGAAAGAGGCACGGTTGATACACTGCGATTTGAAGCCTGAAAACATCCTATTGAAATCCCTT CAATCTCCTCAAATCAAAGTTATCGACTTCGGTTCTGCGTGTCATGAACGGCAAACAGTCTACACCTACATTCAG TCGCGATTCTATCGCTCACCTGAAGTCCTTTTGGGAATGCCTTACACGGCAGCTATCGACATGTGGTCATTGGGC TGCATTGCCGTCGAGCTATTCCTTGGTCTACCTCTTTTCCCTGGTACCAGCGAGTACAACCAGCTAACGAGGATA ATTGAGATGCTAGGGATGCCTCCTTTGAGCATGCTCAATAGCGGCAAGCAAACCAAACTCAATAACCGTGCTGCG TTCATCGACTTCTGCAAAGGCCTCTTGGATCTGAACCCTGTGACACGATGGACTCCACAGCAAGCGCGACTCCAC CCATTCATCACCGGAGAAAAGTTTACAAAACCCTTCGTCCCCGAAGGTCTGGCACCTTCACAACCCTCTTCTTCT TCGTCCCCGAACACCCCCGATCCCAAGCGTCCATACGGCGGTCTCGTTCCGTCTCAGCCGAAGGGCACGCGGGCT TATCAGGACGCGGCCACTTACAACCATCATCTCGCTCAGCACCAGGCATATACCGCCCAGCAGGCGTCGCAGGCT GCGAACACTTTCCGAAACCCGTACATCAATCCACCGGCTCAGCAACAGCAATCGCAGCAACAACATCAACAACAG CCACCATCCCAACCCCCTGTAGCACAAACGACCTATACAAACCCTCCTGCGGACCCGTACCACCCTCAGTCGCAA CAGCAACAGTCTCAGTCACAGCATCTCTCCGGCCAGTATGGAAGTGGAGCGGCACAAACTGCTCACCGTGCCCTT GCACACGCGAACTCTGCGAATCAATTGGGTTCTGGAGCATCTGGGTCACAATATCCCTCCCATTCGTCCGCCACA AACCTCTCGTCTTCGCATCTAAACCCGAATGTGTCGTCTGGTTCTTACTACCCCAATTCTCGCGCTCGGGCCAAC ACGATCAACCAGATGGATACCATTCCACCTGCTCTCGCTCGACTGCAACACATGAACCAAGACATAATCGGTGGA CGAAATGCATTGACGCCGGTCTTGAACCGTGATGACGCCATGAAAGAATGGGAGCGACGCCAATCTGGCAAACCT CCTGCTGCTCAACCGTACCCGCAATTGGAGTACCTGCAGCAGCAGGCGGAGATCGTAGCTGCGTCTGGCTTGGCC AACTGGGCGAGTGGTCCTCATACAAGGTACCCGGCGCAACCGTCAAAGTTGCAACACTCGTACCAACCTCATACG ATTATGGTTGACGATGAGAACGGGAATACCTCTAGGAGGGATGTGGTGATGTCCAATGTTCGCGCAGCTGCTGGT GGTGGTGCACGAACCGACCAGCAATCGGGGCTTGGCTCATACAGCGGGAGCACTGGAAACCTCATTACGAGTCCA CCACAAGCTTACTCCGGTAACACCGCGGCAGGAAGTCGGTACACGACAAGCTATGGGCAACCACAGCACCCGCCA CCGCCAGCATCTTCCAACTCGTTCGACACGGTAGATCGGCGGACGGATATCGGGATGTACGTGCCTATGCAGCCG GATCAGTACCAAGGCTATCCTGCTTCGACTTCGACGAACAGGCACGCTCCTCCGGCTGGACCGCCGGTTCCGACA TCGTTCTACGGACCTTCGATCGTTCCTTCAGGATCCCAACAACAGAGGAACCCGTTCAACGTGCAGGAGAACGCG CAGCAGTCTATGGGTCAACCTAAGGACAACCGCAACTGGCCCCGATAAGTCGCCTAAGCATTGTGAAGGGGATGG ATGGGGATATGGACGGAAAGTTCTTTTGGTGGCGTCCGTTGGGCGGGGGTTTGGGGTCGAGCGAATGCGGCAGCG GTGATTGATTGTGCTCTGTGCGCGATTTTGCGATCCTTTATTCTTGTCCTCGTCGGACTTGTTGTTTTCCATTTT ATCTCTTTTCCTACCTCGCACCCGTGTTGTTTTTTCTTCTTCTGTAGAGGCTGCTGCCTTGCCTTTTTATTATAT ATTTTT |
| Length | 3456 |
Gene
| Sequence id | CC1G_14245T0 |
|---|---|
| Sequence |
>CC1G_14245T0 ATGCAAGACTCTAACGAATCGTCGTTCGACCTTCCTCGTTGGCAGACCCATGTCGAGCCTGCAGCCCAGGCAACT CCCTACCTTTATGGCCCACCGCCGCCTTCACAGCATTCCATGTCCGGATCGTCACCCCAACGCATCCAGCCAGTC CACCAGAGCCACACAGGTTCTTCAACCAGGCAGCCACGAATTTCTCAGTTGCTCGAGCAGGAACACTCATTAAGC CCGCCATCCAACCAGTATACACCCTCAAACCAGGCCCCATTGTCCCGCAGTGCATCCCTTGGAGGTACCAGCGCA AGTAACCTGGCTTCGCGCCTTGTCAGGCGCCATAATCAACCGGACGATTTGGAAGCCTACAATACTGACAACCAA GGACTATCGGGACCCCGTCAGCAACCCCAACTCTCCCAAAACACGTTTTACAACCCCAGTGTTGGGTATCAGTCA CCATCGATGACAGGGAACGTTTCATCTGGCACGACAGCAGGCTCAACATCCGATTCCTACTCAGATCTCTACTAC AATGGTTCAGCCAGTCAACCACCAAAGAGAATCCAAGATCCCAACCGTGCCGCCGGTCGATCGCCACACCGAGCC GCCAATCCTACCAATTCAACGGGACTCATAGACGCTTACGCTCAACAGCAATCGCAATACTCTCCGACAACAGCA ACGTACTCGTACGGTCCTGGTCCCCCACAATCGACTGGTTATCAGACCCACGGTCGCAGCAACTCCCAGGTCAAG CAAGAGCAAGCGACACCCCCTATAGCAAGCCCTTATGCACCCCAGAATCAGTCCCACCAAGTAAGCAATAGCTCG AAGTCTTATCCCATGGATGTATCGACCACCCCTTCCATTGTACAGACGCCATCACACTTGGCTGCTCATGCTCCA CCTAAGCAGTCGATCTCCAATCCGCCAACGCCAATGTCGTACATGCATGGCCCAGGTTCTCATTATTACCCCCAG GACCAGTCGATGATGGTGGACCCGCCTCCTAAAAGGCGTGCATCAGGGTTCCGCCGCGTGCGGACGTTGCATGAT CTCCAGCCCCGTGTAGAGGCTAACCCTGGGGGTCGTCGAATGGGGAGTGACGGAACCTATCTTTCGGCAAGTCTT CCCTACGTTGCGCTTCCATGCGTGTGTACTCACTGCCCCTCCTTTGTATAGCCTTTGCGGCAACTCACTACAAAC ATCGTCGAGACATACCGGATTTGCAACCCCAGCTATCGCTATGAATCGGCTCATAACCCCAGACGGGTTCTCACC AAGCCGAGCAAACCCGTTCACAATGAAGGGTACGACAACGAGGATTATGATTACATTCTCTACGTCAATGATTGG CTGGGTACTGAAGAGGGCCACAAGTGCGTGCGTTTATCTCCAACTAATGGCCCTCATTAACGCACCTTTTTCAAC GCAGATACCTTATCCTTGATATTCTCGGTCAAGGAACGTTCGGCCAGGTGGTGAAATGCCAGAACATGAAGACAC ACGAGATTGTCGCCGTGAAAGTGATCAAGAACAAGCCCGCGTACTTTAACCAGAGTATGATGGAGGTCACGATCC TAGAGATGGTGAGTTGAGTCGGATTTCGCACCCGAGCTTCGCTGACCGGTTCTATAAGCTTAACAAAACCTGCGA TCCAAACGACGAACACCACCTTCTTCGACTTCGCGATTCATTCATCCATCGAAGTCACCTGTGCCTCGTCTTTGA GCTTCTGTCGTCCAACCTTTACGAGTTGATCAAGCAGAATCAATTCCAGGGTCTGAGTACGCAACTTGTCAAGGT CTTCATGGCCCAGCTTCTCGACGCCTTGACCGTATTGAAAGAGGCACGGTTGATACACTGCGATTTGAAGCCTGA AAACATCCTATTGAAATCGTACGCCATTCCATTCTTATCTTCGAGATACCACGATGTTGAATACTGTCCTAGCCT TCAATCTCCTCAAATCAAAGTTATCGACTTCGGTTCTGCGTGTCATGAACGGCAAACAGTCTACACCTACATTCA GTCGCGATTCTATCGCTCACCTGAAGTCCTTTTGGGAATGCCTTACACGGCAGCTATCGACATGTGGTCATTGGG CTGCATTGCCGTCGAGCTATTCCTTGGTCTACCTCTTTTCCCTGGTACCAGCGAGTACAACCAGCTAACGAGGAT AATTGAGATGCTAGGGTGGGTTTCCTCTACTACAGGTCACGTTGTCTTGCTAAAGACCATTCGTCAGGATGCCTC CTTTGAGCATGCTCAATAGCGGCAAGCAAACCAGTCAGTTCTTCGACTCTTTCGATGTCTATAACCCCCAAACGG GCCAACACGAGAAGAAATATCGCCTCAAGTCCATCGAGCAGTATTCGAGGGAACACAACACCAACGAGCAGCCCG GGAAGCAATATTTCAAGGCTACATCGTTACCCGAACTAATCAATACGGCGCCCATGCCATCTTCCAAGTCGTCAA GGTCACAGCATGAGATTGAGAAAGGCGAGTCCTTCTAGGCACATGTACCCCATGGGATCACATTGATTAACATAT TCCTTTGCTAGAACTCAATAACCGTGCTGCGTTCATCGACTTCTGCAAAGGCCTCTTGGATCTGAACCCTGTGAC ACGATGGACTCCACAGCAAGCGCGACTCCACCCATTCATCACCGGAGAAAAGTTTACAAAACCCTTCGTCGTACG TGCTTCCGTGGCGTTTGGGGTGTCTCTTGTTGATGTTCTTGTGTAGCCCGAAGGTCTGGCACCTTCACAACCCTC TTCTTCTTCGTCCCCGAACACCCCCGATCCCAAGCGTCCATACGGCGGTCTCGTTCCGTCTCAGCCGAAGGGCAC GCGGGCTTATCAGGACGCGGCCACTTACAACCATCATCTCGCTCAGCACCAGGCATATACCGCCCAGCAGGCGTC GCAGGCTGCGAACACTTTCCGAAACCCGTACATCAATCCACCGGCTCAGCAACAGCAATCGCAGCAACAACATCA ACAACAGCCACCATCCCAACCCCCTGTAGCACAAACGACCTATACAAACCCTCCTGCGGACCCGTACCACCCTCA GTCGCAACAGCAACAGTCTCAGTCACAGCATCTCTCCGGCCAGTATGGAAGTGGAGCGGCACAAACTGCTCACCG TGCCCTTGCACACGCGAACTCTGCGAATCAATTGGGTTCTGGAGCATCTGGGTCACAATATCCCTCCCATTCGTC CGCCACAAACCTCTCGTCTTCGCATCTAAACCCGAATGTGTCGTCTGGTTCTTACTACCCCAATTCTCGCGCTCG GGCCAACACGATCAACCAGATGGATACCATTCCACCTGCTCTCGCTCGACTGCAACACATGAACCAAGACATAAT CGGTGGACGAAATGCATTGACGCCGGTCTTGAACCGTGATGACGCCATGAAAGAATGGGAGCGACGCCAATCTGG CAAACCTCCTGCTGCTCAACCGTACCCGCAATTGGAGTACCTGCAGCAGCAGGCGGAGATCGTAGCTGCGTCTGG CTTGGCCAACTGGGCGAGTGGTCCTCATACAAGGTACCCGGCGCAACCGTCAAAGTTGCAACACTCGTACCAACC TCATACGATTATGGTTGACGATGAGAACGGGAATACCTCTAGGAGGGATGTGGTGATGTCCAATGTTCGCGCAGC TGCTGGTGGTGGTGCACGAACCGACCAGCAATCGGGGCTTGGCTCATACAGCGGGAGCACTGGAAACCTCATTAC GAGTCCACCACAAGCTTACTCCGGTAACACCGCGGCAGGAAGTCGGTACACGACAAGCTATGGGCAACCACAGCA CCCGCCACCGCCAGCATCTTCCAACTCGTTCGACACGGTAGATCGGCGGACGGATATCGGGATGTACGTGCCTAT GCAGCCGGATCAGTACCAAGGCTATCCTGCTTCGACTTCGACGAACAGGCACGCTCCTCCGGCTGGACCGCCGGT TCCGACATCGTTCTACGGACCTTCGATCGTTCCTTCAGGATCCCAACAACAGAGGAACCCGTTCAACGTGCAGGA GAACGCGCAGCAGTCTATGGGTCAACCTAAGGACAACCGCAACTGGCCCCGATAAGTCGCCTAAGCATTGTGAAG GGGATGGATGGGGATATGGACGGAAAGTTCTTTTGGTGGCGTCCGTTGGGCGGGGGTTTGGGGTCGAGCGAATGC GGCAGCGGTGATTGATTGTGCTCTGTGCGCGATTTTGCGATCCTTTATTCTTGTCCTCGTCGGACTTGTTGTTTT CCATTTTATCTCTTTTCCTACCTCGCACCCGTGTTGTTTTTTCTTCTTCTGTAGAGGCTGCTGCCTTGCCTTTTT ATTATATATTTTT |
| Length | 4363 |