CC1G_15304
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_15304 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | D6RPY3 | Functional description | STE/STE20/PAKA protein kinase |
| Location | Chr_10:1124477..1128061 | Strand | - |
| Gene length (nt) | 3585 | Transcript length (nt) | 3120 |
| CDS length (nt) | 3120 | Protein length (aa) | 1039 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB23610 | 45.6 | 5.584E-300 | 948 |
| Flammulina velutipes | Flave_chr02AA00405 | 42.4 | 6.109E-245 | 787 |
| Agrocybe aegerita | Agrae_CAA7262091 | 29.7 | 3.956E-191 | 629 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_13540 | 35.4 | 4.033E-189 | 623 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_153572 | 48.2 | 2.862E-161 | 540 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_47208 | 53.3 | 7.2E-151 | 509 |
| Pleurotus ostreatus PC15 | PleosPC15_2_34352 | 51.5 | 8.045E-150 | 506 |
| Schizophyllum commune H4-8 | Schco3_1104624 | 50.5 | 4.785E-136 | 465 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1392944 | 62.5 | 8.775E-133 | 455 |
| Pleurotus ostreatus PC9 | PleosPC9_1_59097 | 62.8 | 7.303E-133 | 455 |
| Lentinula edodes B17 | Lened_B_1_1_2094 | 59.4 | 5.687E-124 | 428 |
| Lentinula edodes NBRC 111202 | Lenedo1_1034100 | 59.4 | 7.187E-124 | 428 |
| Grifola frondosa | Grifr_OBZ74952 | 43 | 5.611E-119 | 413 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_53085 | 43.8 | 8.396E-111 | 388 |
| Auricularia subglabra | Aurde3_1_1240918 | 27.6 | 1.671E-100 | 357 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 12855 |
| Description | STE/STE20/PAKA protein kinase |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| Pfam | PF00786 | P21-Rho-binding domain | IPR000095 | 65 | 101 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 787 | 1014 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR036936 | CRIB domain superfamily |
| IPR000095 | CRIB domain |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR020635 | Tyrosine-protein kinase, catalytic domain |
| IPR000719 | Protein kinase domain |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004713 | protein tyrosine kinase activity | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
KEGG
| KEGG Orthology |
|---|
| K19833 |
EggNOG
| COG category | Description |
|---|---|
| T | Protein tyrosine kinase |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
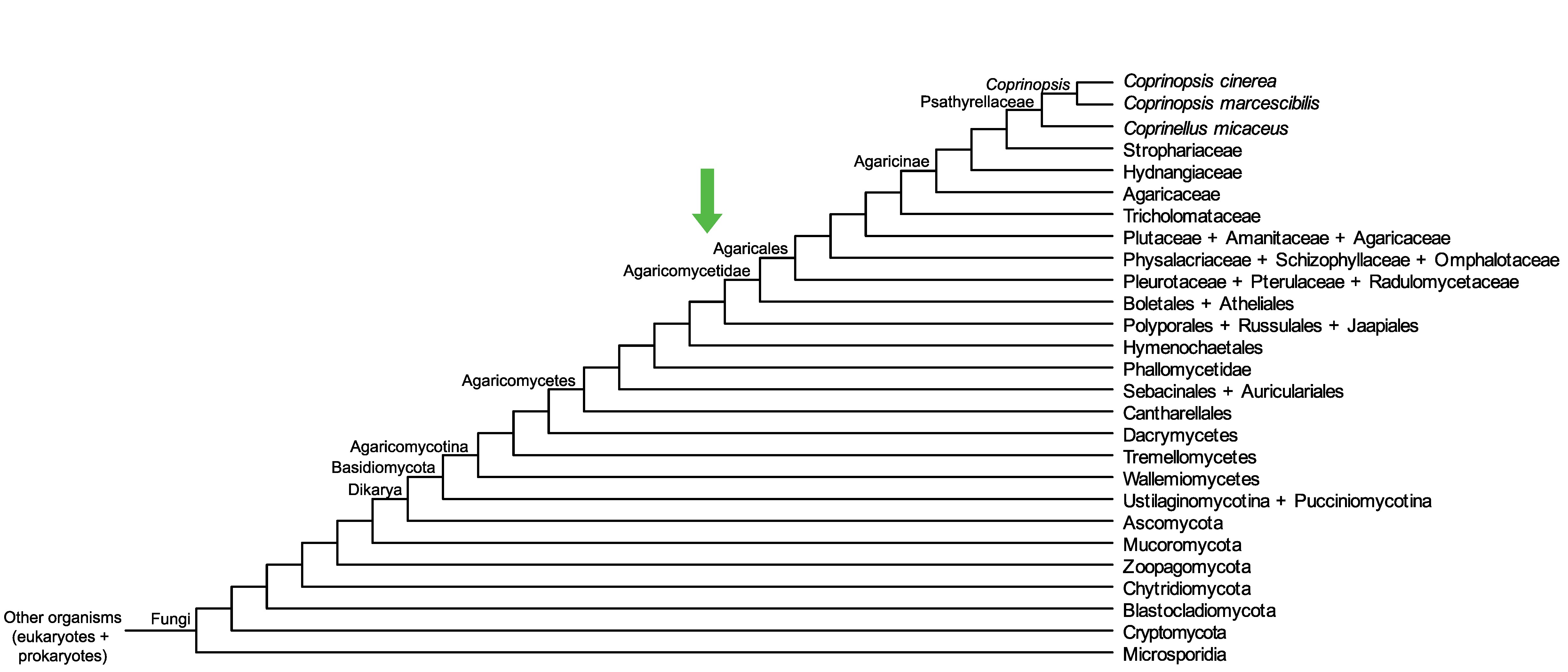
Conservation of CC1G_15304 across fungi.
Arrow shows the origin of gene family containing CC1G_15304.
Protein
| Sequence id | 12855 |
|---|---|
| Sequence |
>12855 MSLTSSIASGLSSPPTEGKRPQSRGKEKALSFLKFGKRSPKSPPTKDASWDSAVPPLPSNGDDGISTPFNFQHNI HVNEGLVGLPPTWSAALSQAGFSDEEIIAIHNRRAAGSRSPNSQYVLNARPPSPRIPHPYQQSASNVPIIAQPGP RTTSLPRQVSDASLRSTSTRQRHPIPFGSPASASTASLHSSNAGSISNIKAVRQGASQDHSSRNHTPQLSISYSS DSNHSGVSGEDVYQQSRNGNFPKDVSTPPGKPAHAANPSIAQSFMSQASSLLNGHSHNRNESNASSTSKRLFGSQ PSLWSSPSSSSTASRPQTAANTSTSSNHSNAAVTQPTDNNASPEASPPQPKRTNALPPRLSLHQASGSGDLSAWA GMLLSGLSSDLDDKLTLGPSPLGPTPLTPQSAPASAATQGPSSFTVSNRPTHTSHSRSLGGESSKARPEPLSELE EPIDNDAQYANLSPPWTGDAGSSSPLWSEIEGILSQGRSPTASEDRHEPGPYSAALAETFSPTLPFSPEEDRMAQ ERRLRNEASRERLEREEDLNRLSVNTARPNRDSSRSIPPTPIVPPPRQLPNRPAPIDAGHSPSPPNSSFDSEESS ASSSQSQDRYPTPTTANSTSSPLRYYLEPSPSPSQASFSPVVARHKEYPNVPPAYDIDEDLDEDDEEGTNLIIPH QIITAPSPQANRPTIVIENVSPGGALSTALPTGTPASPFQRYRGWLSEVVQPLEEYIDEGVDPRDHYLDLKEIAE GESGSVFSARLIQKDADKLRLPAHVKAQDADDFANNREVLVAIKSVAIVPSGSPKLKDLQHELGLMKGLHHENVI GLDSLYVDFLEDTLWIRMELMERSLADIIGLVDAGLMLPDRMMARFASDILSGLDYLQRHHIAHRDVRSDNLLIN KHGVLKLTDFANAVQVSAQNPMRTEPAGVLYWQAPEVRSPPYNAMKVDVWSLGATVWEMAETQPPFADTNEFGDR WPPLSRPQLVSPAFHEFLRLCSEPAASRPTAGELLKTPFVKNACGRAVIVQLLSQCIAIESAFE |
| Length | 1039 |
Coding
| Sequence id | CC1G_15304T0 |
|---|---|
| Sequence |
>CC1G_15304T0 ATGTCGCTAACGTCGTCGATAGCCTCCGGTTTATCCTCGCCACCCACGGAAGGCAAAAGACCACAGTCCAGGGGA AAGGAAAAGGCGCTCTCCTTTTTGAAGTTTGGCAAACGGAGTCCCAAATCGCCTCCAACCAAGGACGCCAGTTGG GACAGCGCCGTACCTCCGTTACCGTCGAACGGCGACGATGGGATCTCCACGCCGTTCAATTTCCAGCACAACATT CACGTTAACGAAGGACTCGTTGGCCTCCCTCCAACTTGGTCAGCAGCGCTGTCGCAAGCAGGGTTTTCTGACGAG GAAATAATCGCCATCCACAACCGTCGCGCAGCAGGTTCGCGATCCCCGAATTCCCAATATGTGCTGAACGCTCGT CCACCTTCTCCCCGTATACCCCACCCGTATCAGCAGAGTGCCTCCAATGTCCCGATCATTGCGCAGCCTGGCCCA AGAACGACGTCTTTGCCCAGACAGGTCTCGGACGCATCGCTGAGGAGCACTTCGACGCGCCAGCGGCACCCGATA CCCTTTGGTAGCCCTGCGTCCGCGTCAACAGCGTCGTTACATTCCAGCAATGCCGGAAGTATCAGCAACATCAAA GCGGTTCGACAAGGTGCTTCTCAAGACCACTCTAGTCGGAACCACACTCCGCAACTATCAATTTCTTATTCGTCC GACTCCAATCACAGCGGTGTCAGTGGTGAAGATGTCTATCAGCAGTCGAGGAATGGCAATTTCCCAAAGGACGTG TCAACACCTCCCGGTAAACCTGCACACGCTGCCAACCCTTCGATCGCTCAGTCATTCATGTCTCAAGCTTCATCA CTTCTGAATGGTCACAGTCACAATCGTAACGAATCAAACGCCTCTTCGACATCCAAGCGCCTGTTCGGGAGCCAA CCTTCCCTATGGTCTTCGCCGTCGTCATCTTCAACTGCAAGTCGACCACAAACAGCTGCCAATACGTCTACTTCT AGCAACCATTCAAATGCGGCGGTTACTCAACCGACCGACAACAACGCCAGTCCGGAAGCGAGCCCTCCTCAACCG AAACGCACAAACGCGTTACCTCCAAGACTATCCTTACATCAAGCAAGCGGAAGTGGGGATCTTTCGGCATGGGCG GGCATGCTGCTTTCTGGACTATCATCCGACCTTGATGACAAGCTGACCTTGGGCCCTTCACCCCTGGGCCCAACA CCACTGACACCCCAGTCAGCGCCTGCTAGTGCTGCAACTCAAGGGCCTTCCTCGTTTACAGTTTCAAACCGACCC ACGCATACCTCCCATTCGCGTTCCCTAGGCGGCGAAAGTTCAAAAGCGAGACCTGAACCATTGTCAGAGTTGGAG GAACCTATTGATAATGATGCTCAGTATGCCAATCTTTCTCCGCCATGGACTGGAGACGCTGGTAGTAGCTCCCCA CTGTGGTCAGAAATCGAAGGCATTCTGAGCCAAGGGCGGTCGCCCACGGCCAGTGAAGATCGCCACGAACCTGGC CCTTATTCTGCAGCCCTTGCCGAAACCTTCTCTCCGACACTGCCCTTCTCTCCCGAGGAAGATCGGATGGCACAG GAGCGTAGGCTGAGGAACGAGGCGTCGAGGGAGCGATTGGAGCGGGAGGAGGACTTGAACCGCCTGAGCGTCAAC ACTGCTCGGCCTAACCGAGATTCAAGTCGAAGCATCCCTCCAACGCCCATCGTCCCTCCTCCAAGGCAGCTACCC AATCGCCCAGCTCCTATCGATGCTGGTCATTCACCATCTCCTCCGAACTCTTCATTCGACAGCGAAGAAAGCTCT GCATCAAGTTCCCAATCGCAGGATCGTTACCCTACACCGACGACGGCCAACTCAACGTCTTCTCCCCTCCGTTAC TACCTGGAACCTTCACCATCTCCTTCGCAAGCATCGTTCTCGCCGGTAGTAGCACGCCACAAGGAGTATCCTAAC GTCCCACCGGCGTATGACATCGACGAAGATCTCGACGAGGACGACGAGGAGGGAACCAACCTCATTATTCCGCAC CAAATCATCACCGCCCCATCTCCTCAGGCCAACCGACCGACAATCGTCATCGAGAACGTCTCACCGGGCGGAGCG CTCTCCACAGCTCTTCCCACCGGCACACCAGCCTCTCCCTTCCAACGCTACCGAGGTTGGCTATCCGAAGTCGTC CAACCACTAGAAGAATACATCGACGAAGGCGTCGATCCTCGGGACCATTACCTAGACCTGAAAGAAATCGCAGAA GGCGAAAGCGGCTCCGTCTTCTCTGCCCGACTTATCCAGAAAGACGCAGACAAACTCCGGCTACCTGCGCACGTC AAGGCTCAGGACGCAGACGACTTTGCCAACAACCGGGAAGTGTTAGTGGCTATCAAGAGTGTGGCGATTGTGCCC TCAGGGTCGCCCAAACTCAAGGACCTACAGCACGAGCTTGGTCTCATGAAGGGGTTGCACCACGAAAACGTCATC GGTCTAGATTCTCTCTATGTCGATTTCTTAGAAGATACCCTGTGGATAAGGATGGAACTAATGGAAAGGAGTCTG GCGGATATTATTGGTCTTGTGGATGCTGGGTTGATGCTGCCGGATCGGATGATGGCCAGGTTTGCCAGTGATATC TTGAGCGGCCTCGATTATCTACAACGACATCACATTGCCCATCGCGACGTGCGATCGGATAACTTGCTGATAAAC AAGCATGGGGTTCTGAAACTAACCGACTTTGCGAATGCTGTGCAAGTGTCTGCTCAAAATCCAATGCGGACAGAG CCGGCTGGTGTGCTGTACTGGCAGGCTCCAGAAGTAAGAAGCCCACCGTACAATGCTATGAAGGTCGATGTTTGG TCTCTGGGGGCCACCGTCTGGGAGATGGCCGAAACGCAACCACCTTTTGCCGACACTAACGAGTTTGGAGATCGC TGGCCACCACTCTCTAGACCCCAGCTGGTCTCACCCGCTTTCCACGAGTTCCTCCGGCTCTGCTCTGAACCTGCT GCAAGTCGTCCTACGGCTGGGGAGCTCTTGAAGACACCTTTCGTCAAGAACGCTTGCGGACGAGCGGTCATCGTC CAACTTTTGTCTCAGTGCATAGCCATCGAGTCTGCTTTCGAG |
| Length | 3120 |
Transcript
| Sequence id | CC1G_15304T0 |
|---|---|
| Sequence |
>CC1G_15304T0 ATGTCGCTAACGTCGTCGATAGCCTCCGGTTTATCCTCGCCACCCACGGAAGGCAAAAGACCACAGTCCAGGGGA AAGGAAAAGGCGCTCTCCTTTTTGAAGTTTGGCAAACGGAGTCCCAAATCGCCTCCAACCAAGGACGCCAGTTGG GACAGCGCCGTACCTCCGTTACCGTCGAACGGCGACGATGGGATCTCCACGCCGTTCAATTTCCAGCACAACATT CACGTTAACGAAGGACTCGTTGGCCTCCCTCCAACTTGGTCAGCAGCGCTGTCGCAAGCAGGGTTTTCTGACGAG GAAATAATCGCCATCCACAACCGTCGCGCAGCAGGTTCGCGATCCCCGAATTCCCAATATGTGCTGAACGCTCGT CCACCTTCTCCCCGTATACCCCACCCGTATCAGCAGAGTGCCTCCAATGTCCCGATCATTGCGCAGCCTGGCCCA AGAACGACGTCTTTGCCCAGACAGGTCTCGGACGCATCGCTGAGGAGCACTTCGACGCGCCAGCGGCACCCGATA CCCTTTGGTAGCCCTGCGTCCGCGTCAACAGCGTCGTTACATTCCAGCAATGCCGGAAGTATCAGCAACATCAAA GCGGTTCGACAAGGTGCTTCTCAAGACCACTCTAGTCGGAACCACACTCCGCAACTATCAATTTCTTATTCGTCC GACTCCAATCACAGCGGTGTCAGTGGTGAAGATGTCTATCAGCAGTCGAGGAATGGCAATTTCCCAAAGGACGTG TCAACACCTCCCGGTAAACCTGCACACGCTGCCAACCCTTCGATCGCTCAGTCATTCATGTCTCAAGCTTCATCA CTTCTGAATGGTCACAGTCACAATCGTAACGAATCAAACGCCTCTTCGACATCCAAGCGCCTGTTCGGGAGCCAA CCTTCCCTATGGTCTTCGCCGTCGTCATCTTCAACTGCAAGTCGACCACAAACAGCTGCCAATACGTCTACTTCT AGCAACCATTCAAATGCGGCGGTTACTCAACCGACCGACAACAACGCCAGTCCGGAAGCGAGCCCTCCTCAACCG AAACGCACAAACGCGTTACCTCCAAGACTATCCTTACATCAAGCAAGCGGAAGTGGGGATCTTTCGGCATGGGCG GGCATGCTGCTTTCTGGACTATCATCCGACCTTGATGACAAGCTGACCTTGGGCCCTTCACCCCTGGGCCCAACA CCACTGACACCCCAGTCAGCGCCTGCTAGTGCTGCAACTCAAGGGCCTTCCTCGTTTACAGTTTCAAACCGACCC ACGCATACCTCCCATTCGCGTTCCCTAGGCGGCGAAAGTTCAAAAGCGAGACCTGAACCATTGTCAGAGTTGGAG GAACCTATTGATAATGATGCTCAGTATGCCAATCTTTCTCCGCCATGGACTGGAGACGCTGGTAGTAGCTCCCCA CTGTGGTCAGAAATCGAAGGCATTCTGAGCCAAGGGCGGTCGCCCACGGCCAGTGAAGATCGCCACGAACCTGGC CCTTATTCTGCAGCCCTTGCCGAAACCTTCTCTCCGACACTGCCCTTCTCTCCCGAGGAAGATCGGATGGCACAG GAGCGTAGGCTGAGGAACGAGGCGTCGAGGGAGCGATTGGAGCGGGAGGAGGACTTGAACCGCCTGAGCGTCAAC ACTGCTCGGCCTAACCGAGATTCAAGTCGAAGCATCCCTCCAACGCCCATCGTCCCTCCTCCAAGGCAGCTACCC AATCGCCCAGCTCCTATCGATGCTGGTCATTCACCATCTCCTCCGAACTCTTCATTCGACAGCGAAGAAAGCTCT GCATCAAGTTCCCAATCGCAGGATCGTTACCCTACACCGACGACGGCCAACTCAACGTCTTCTCCCCTCCGTTAC TACCTGGAACCTTCACCATCTCCTTCGCAAGCATCGTTCTCGCCGGTAGTAGCACGCCACAAGGAGTATCCTAAC GTCCCACCGGCGTATGACATCGACGAAGATCTCGACGAGGACGACGAGGAGGGAACCAACCTCATTATTCCGCAC CAAATCATCACCGCCCCATCTCCTCAGGCCAACCGACCGACAATCGTCATCGAGAACGTCTCACCGGGCGGAGCG CTCTCCACAGCTCTTCCCACCGGCACACCAGCCTCTCCCTTCCAACGCTACCGAGGTTGGCTATCCGAAGTCGTC CAACCACTAGAAGAATACATCGACGAAGGCGTCGATCCTCGGGACCATTACCTAGACCTGAAAGAAATCGCAGAA GGCGAAAGCGGCTCCGTCTTCTCTGCCCGACTTATCCAGAAAGACGCAGACAAACTCCGGCTACCTGCGCACGTC AAGGCTCAGGACGCAGACGACTTTGCCAACAACCGGGAAGTGTTAGTGGCTATCAAGAGTGTGGCGATTGTGCCC TCAGGGTCGCCCAAACTCAAGGACCTACAGCACGAGCTTGGTCTCATGAAGGGGTTGCACCACGAAAACGTCATC GGTCTAGATTCTCTCTATGTCGATTTCTTAGAAGATACCCTGTGGATAAGGATGGAACTAATGGAAAGGAGTCTG GCGGATATTATTGGTCTTGTGGATGCTGGGTTGATGCTGCCGGATCGGATGATGGCCAGGTTTGCCAGTGATATC TTGAGCGGCCTCGATTATCTACAACGACATCACATTGCCCATCGCGACGTGCGATCGGATAACTTGCTGATAAAC AAGCATGGGGTTCTGAAACTAACCGACTTTGCGAATGCTGTGCAAGTGTCTGCTCAAAATCCAATGCGGACAGAG CCGGCTGGTGTGCTGTACTGGCAGGCTCCAGAAGTAAGAAGCCCACCGTACAATGCTATGAAGGTCGATGTTTGG TCTCTGGGGGCCACCGTCTGGGAGATGGCCGAAACGCAACCACCTTTTGCCGACACTAACGAGTTTGGAGATCGC TGGCCACCACTCTCTAGACCCCAGCTGGTCTCACCCGCTTTCCACGAGTTCCTCCGGCTCTGCTCTGAACCTGCT GCAAGTCGTCCTACGGCTGGGGAGCTCTTGAAGACACCTTTCGTCAAGAACGCTTGCGGACGAGCGGTCATCGTC CAACTTTTGTCTCAGTGCATAGCCATCGAGTCTGCTTTCGAGTAA |
| Length | 3120 |
Gene
| Sequence id | CC1G_15304T0 |
|---|---|
| Sequence |
>CC1G_15304T0 ATGTCGCTAACGTCGTCGATAGCCTCCGGTTTATCCTCGCCACCCACGGAAGGCAAAAGACCACAGTCCAGGGGA AAGGAAAAGGCGCTCTCCTTTTTGAAGTTTGGCAAACGGAGTCCCAAATCGCCTCCAACCAAGGACGCCAGTTGG GACAGCGCCGTACCTCCGTTACCGTCGAACGGCGACGATGGGATCTCCACGCCGTTCAATTTCCAGGTCAGTCCA AGTGTAGACGCTTAGTGTTCAACCCTGACGTTTTGGCCATCCACTCCAGCACAACATTCACGTTAACGAAGGGTG AGTGAGAATCTAGATGTGATCCGTTTCCCTACTCACACCACGGTAGACTCGTTGGCCTCCCTCCAACTTGGTCAG CAGCGCTGTCGCAAGCAGGGTTTTCTGACGAGGAAATAATCGCCATCCACAACCGTCGCGCAGCAGGTTCGCGAT CCCCGAATTCCCAATATGTGCTGAACGCTCGTCCACCTTCTCCCCGTATACCCCACCCGTATCAGCAGAGTGCCT CCAATGTCCCGATCATTGCGCAGCCTGGCCCAAGAACGACGTCTTTGCCCAGACAGGTCTCGGACGCATCGCTGA GGAGCACTTCGACGCGCCAGCGGCACCCGATACCCTTTGGTAGCCCTGCGTCCGCGTCAACAGCGTCGTTACATT CCAGCAATGCCGGAAGTATCAGCAACATCAAAGCGGTTCGACAAGGTGCTTCTCAAGACCACTCTAGTCGGAACC ACACTCCGCAACTATCAATTTCTTATTCGTCCGACTCCAATCACAGCGGTGTCAGTGGTGAAGATGTCTATCAGC AGTCGAGGAATGGCAATTTCCCAAAGGACGTGTCAACACCTCCCGGTAAACCTGCACACGCTGCCAACCCTTCGA TCGCTCAGTCATTCATGTCTCAAGCTTCATCACTTCTGAATGGTCACAGTCACAATCGTAACGAATCAAACGCCT CTTCGACATCCAAGCGCCTGTTCGGGAGCCAACCTTCCCTATGGTCTTCGCCGTCGTCATCTTCAACTGCAAGTC GACCACAAACAGCTGCCAATACGTCTACTTCTAGCAACCATTCAAATGCGGCGGTTACTCAACCGACCGACAACA ACGCCAGTCCGGAAGCGAGCCCTCCTCAACCGAAACGCACAAACGCGTTACCTCCAAGACTATCCTTACATCAAG CAAGCGGAAGTGGGGATCTTTCGGCATGGGCGGGCATGCTGCTTTCTGGACTATCATCCGACCTTGATGACAAGC TGACCTTGGGCCCTTCACCCCTGGGCCCAACACCACTGACACCCCAGTCAGCGCCTGCTAGTGCTGCAACTCAAG GGCCTTCCTCGTTTACAGTTTCAAACCGACCCACGCATACCTCCCATTCGCGTTCCCTAGGCGGCGAAAGTTCAA AAGCGAGACCTGAACCATTGTCAGAGTTGGAGGAACCTATTGATAATGATGCTCAGTATGCCAATCTTTCTCCGC CATGGACTGGAGACGCTGGTAGTAGCTCCCCACTGTGGTCAGAAATCGAAGGCATTCTGAGCCAAGGGCGGTCGC CCACGGCCAGTGAAGATCGCCACGAACCTGGCCCTTATTCTGCAGCCCTTGCCGAAACCTTCTCTCCGACACTGC CCTTCTCTCCCGAGGAAGATCGGATGGCACAGGAGCGTAGGCTGAGGAACGAGGCGTCGAGGGAGCGATTGGAGC GGGAGGAGGACTTGAACCGCCTGAGCGTCAACACTGCTCGGCCTAACCGAGATTCAAGTCGAAGCAGTACGTCGA CGGTGGGGCCAACGACGATTGTGCGAAACGTCTCCGTGGCTAGACGAGCAGGTGCATTCGTCATCAACAACTCGA ACCCTGTTTCTCCAATTGACCACGATGCATCCTCAGTCCCTCCAACGCCCATCGTCCCTCCTCCAAGGCAGCTAC CCAATCGCCCAGCTCCTATCGATGCTGGTCATTCACCATCTCCTCCGAACTCTTCATTCGACAGCGAAGAAAGCT CTGCATCAAGTTCCCAATCGCAGGATCGTTACCCTACACCGACGACGGCCAACTCAACGTCTTCTCCCCTCCGTT ACTACCTGGAACCTTCACCATCTCCTTCGCAAGCATCGTTCTCGCCGGTAGTAGCACGCCACAAGGAGTATCCTA ACGTCCCACCGGCGTATGACATCGACGAAGATCTCGACGAGGACGACGAGGAGGGAACCAACCTCATTATTCCGC ACCAAATCATCACCGCCCCATCTCCTCAGGCCAACCGACCGACAATCGTCATCGAGAACGTCTCACCGGGCGGAG CGCTCTCCACAGCTCTTCCCACCGGCACACCAGCCTCTCCCTTCCAACGCTACCGAGGTTGGCTATCCGAAGTCG TCCAACCACTAGAAGAATACATCGACGAAGGCGTCGATCCTCGGGACCATTACCTAGACCTGAAAGAAATCGCAG AAGGCGAAAGCGGCTCCGTCTTCTCTGCCCGACTTATCCAGAAAGACGCAGACAAACTCCGGCTACCTGCGCACG TCAAGGCTCAGGACGCAGACGACTTTGCCAACAACCGGGAAGTGTTAGTGGCTATCAAGAGTGTGGCGATTGTGC CCTCAGGGTCGCCCAAACTCAAGGACCTACAGCACGAGCTTGGTCTCATGAAGGGGTTGCACCACGAAAACGTCA TCGGTCTAGATTCTCTCTATGTCGATTTCTTAGAAGATACCCTGTGGATAAGGATGGAACTAATGGAAAGGAGTC TGGCGGATATTATTGGTCTTGTGGATGCTGGGTTGATGCTGCCGGATCGGATGATGGCCAGGTTTGCCAGTGATG TATGTCCTTCCTTTTTGCGTTCTTCCTGCCCCTCTTTGTGCTGACTTTGTGCTCTCGTCTTGTAGATCTTGAGCG GCCTCGATTATCTACAACGACATCACATTGCCCATCGCGACGTGCGATCGGATAACTTGCTGATAAACAAGCATG GGGTTCTGAAACTAAGTAAGCAACTTCGATCTTCGTTCATTCAAACTAGTTCATCTAAGTGCGTGTTTCCAGCCG ACTTTGCGAATGCTGTGCAAGTGTCTGCTCAAAATCCAATGCGGACAGAGCCGGCTGGTGTGCTGTACTGGCAGG CTCCAGAAGTAAGAAGGTCAGTCATGCTTTGTATTATCACTTCCCGATGTCCTGAGGTTTGCTAACATTCCTTTC AGCCCACCGTACAATGCTATGAAGGTCGATGTTTGGTCTCTGGGGGCCACCGTCTGGGAGATGGCCGAAACGCAA CCACCTTTTGCCGACACTAACGAGTTTGGAGATCGCTGGCCACCACTCTCTAGACCCCAGCTGGTCTCACCCGCT TTCCACGAGTTCCTCCGGCTCTGCTCTGAACCTGCTGCAAGTCGTCCTACGGCTGGGGAGCTCTTGAAGGTAGGC ATCTTCATTGACCTTGTCCGTGTTTCTGTAACTCACATCAATCTCCAGACACCTTTCGTCAAGAACGCTTGCGGA CGAGCGGTCATCGTCCAACTTTTGTCTCAGTGCATAGCCATCGAGTCTGCTTTCGAGTAA |
| Length | 3585 |