CC1G_15592
Coprinopsis cinerea Okoyama 7
General data
| Systematic name | CC1G_15592 | Strain | Coprinopsis cinerea A43mutB43mut pab1-1 #326 |
|---|---|---|---|
| Standard name | - | Synonyms | |
| Uniprot id | D6RN80 | Functional description | Autophagy-related protein 1 (EC 2.7.11.1) |
| Location | Chr_6:1341048..1343990 | Strand | + |
| Gene length (nt) | 2943 | Transcript length (nt) | 2607 |
| CDS length (nt) | 2607 | Protein length (aa) | 868 |
Reciprocal best hits in model fungi
| Strain name | Gene / Protein name |
|---|---|
| No records | |
Orthologs in mushroom models
| Strain name | Gene / Protein name | Pident | E-value | Bits |
|---|---|---|---|---|
| Hypsizygus marmoreus strain 51987-8 | Hypma_RDB17199 | 75.4 | 0 | 1313 |
| Agrocybe aegerita | Agrae_CAA7263301 | 76 | 0 | 1299 |
| Pleurotus eryngii ATCC 90797 | Pleery1_1447819 | 70.4 | 0 | 1225 |
| Lentinula edodes W1-26 v1.0 | Lentinedodes1_10401 | 71.1 | 0 | 1223 |
| Lentinula edodes NBRC 111202 | Lenedo1_1074014 | 68.7 | 0 | 1208 |
| Lentinula edodes B17 | Lened_B_1_1_11884 | 69.4 | 0 | 1172 |
| Flammulina velutipes | Flave_chr01AA00389 | 67.2 | 0 | 1123 |
| Ganoderma sp. 10597 SS1 v1.0 | Gansp1_120964 | 66.8 | 0 | 1118 |
| Grifola frondosa | Grifr_OBZ76318 | 62.7 | 0 | 1075 |
| Schizophyllum commune H4-8 | Schco3_2641378 | 57.2 | 6.272E-304 | 955 |
| Auricularia subglabra | Aurde3_1_1405482 | 46.8 | 2.971E-252 | 794 |
| Pleurotus ostreatus PC15 | PleosPC15_2_1051574 | 70.2 | 3.609E-184 | 595 |
| Agaricus bisporus var bisporus (H97) | Agabi_varbisH97_2_187564 | 67.5 | 2.308E-176 | 572 |
| Agaricus bisporus var. burnettii JB137-S8 | Agabi_varbur_1_121407 | 67.2 | 1.161E-175 | 570 |
| Pleurotus ostreatus PC9 | PleosPC9_1_44366 | 79.5 | 8.633E-169 | 550 |
Expression
| Name | Summary | Attribution | Assay type | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Coprinopsis cinerea mycelia exposed to different biotic and abiotic stress conditions | Identification of a Novel Nematotoxic Protein in Coprinopsis cinerea | Plaza et al. 2016 | RNA-seq | |||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||
General data
| Systematic name | - |
|---|---|
| Protein id | 13143 |
| Description | Autophagy-related protein 1 (EC 2.7.11.1) |
Annotation summary
Conserved domains
| Analysis | Signature accession | Signature description | InterPro Accession | Start | End |
|---|---|---|---|---|---|
| CDD | cd14009 | STKc_ATG1_ULK_like | - | 26 | 315 |
| Pfam | PF00069 | Protein kinase domain | IPR000719 | 22 | 315 |
| Pfam | PF12063 | Domain of unknown function (DUF3543) | IPR022708 | 562 | 816 |
SignalP
| Prediction | Start | End | Score |
|---|---|---|---|
| No records | |||
Transmembrane domains
| Domain n | Start | End | Length |
|---|---|---|---|
| No records | |||
InterPro
| Accession | Description |
|---|---|
| IPR022708 | Serine/threonine-protein kinase Atg1-like, tMIT domain |
| IPR000719 | Protein kinase domain |
| IPR045269 | Serine/threonine-protein kinase Atg1-like |
| IPR008271 | Serine/threonine-protein kinase, active site |
| IPR011009 | Protein kinase-like domain superfamily |
| IPR017441 | Protein kinase, ATP binding site |
GO
| Go id | Term | Ontology |
|---|---|---|
| GO:0004674 | protein serine/threonine kinase activity | MF |
| GO:0004672 | protein kinase activity | MF |
| GO:0005524 | ATP binding | MF |
| GO:0006468 | protein phosphorylation | BP |
| GO:0006914 | autophagy | BP |
KEGG
| KEGG Orthology |
|---|
| K08269 |
EggNOG
| COG category | Description |
|---|---|
| O | Domain of unknown function (DUF3543) |
| T | Domain of unknown function (DUF3543) |
| U | Domain of unknown function (DUF3543) |
CAZy
| Class | Family | Subfamily |
|---|---|---|
| No records | ||
Transcription factor
| Group |
|---|
| No records |
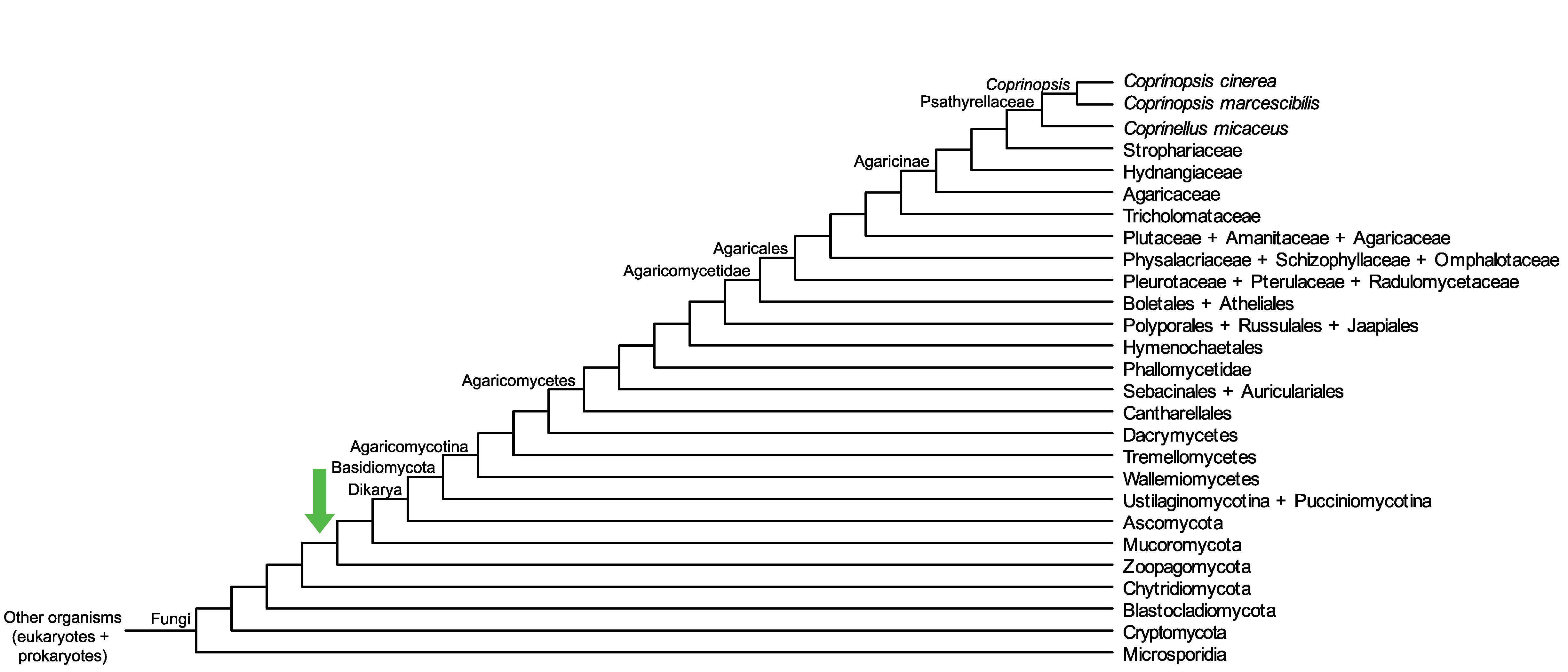
Conservation of CC1G_15592 across fungi.
Arrow shows the origin of gene family containing CC1G_15592.
Protein
| Sequence id | 13143 |
|---|---|
| Sequence |
>13143 MPPIPGPSSSSNDSSDAKPYIIVSDIGRGSFATVYKGYHEETRLQVAIKAVKRDNLSARLLDNLQSEIQILKSLS HRHITKLIDIVRAEKNIYLIMEYCAGGDLTNYIKKRGRVEGLEYIPAPGEPPQYYPHPRSGGLDEIVLRSFLRQL ARALKFLRHRDLIHRDIKPQNLLLNPAPPEELARGHPLGVPILKVADFGFARSLPNAMMAETLCGSPLYMAPEIL RYEKYDAKADLWSVGAVLYEIATGRAPFRAQNHIELLKKIEQSKGLKFPDEDPKTSAEATPVPADIKKLIRALLK RNPIERASFEEFFNSTALAKSKFPRPREPVAAANAEEDHNGRPPTPDHHKDIPPEVLDPNALIPPSKFNWRRPTN GDGTEPAPNAKPVEKARRNKGLSTEGSFIPGETEEDGMLRREYVLVGDTRAVEFNRAVDEINTLPRKPLHDRKIP STPEDSPRQEYPIPNVTNPTTPHNITFPPPPNVNAPPSLSSSPSSNASRAAASALNRALSLATKKLFGTSRRQPS ISSPVHEVSSNTSPPSSPRRPQIIALDTAGERDPLEDELLANLEELAQKTDVLTRWADEMYEYVKAVPQKPLPDP TKFVKREGEGEKHARRRKLADMEAEYNAVTCVAVYMLLMSFSQKGIDKLRNFQEHMNMRHPDGDFVVSEGFDAGA SFDLLMKVIMEKCDVDYAIWVAFSWFKDHFIKCNDRAELVKTWLPAQYDGPKAWLDQLVYDRALMLSRTAARKEL LDQAAAPDECEKLYEESLWCLYALQDDLLQTGNPFMEEDKETIGTSDDGAGIKRTKLRLVRCRARMAMNDRDRII DARADQNLADVARIPAPWDVKPSPSSTSSPTSATVRSPTSPVK |
| Length | 868 |
Coding
| Sequence id | CC1G_15592T0 |
|---|---|
| Sequence |
>CC1G_15592T0 ATGCCACCCATACCTGGCCCTTCGTCCTCGAGCAATGATTCGAGCGACGCAAAGCCCTATATCATCGTTTCTGAC ATTGGAAGGGGGAGTTTCGCTACTGTGTACAAAGGATATCATGAGGAAACGCGGTTGCAGGTCGCCATCAAGGCT GTGAAACGGGACAACCTCAGCGCCAGGCTCTTGGACAACCTGCAAAGCGAGATTCAAATCCTAAAGAGCCTGTCC CATCGACACATAACGAAGCTGATTGACATTGTGCGCGCCGAGAAGAACATCTACCTTATCATGGAGTATTGCGCG GGAGGTGACTTGACGAACTATATCAAGAAACGAGGGCGGGTAGAAGGATTGGAATACATTCCTGCACCAGGAGAA CCGCCACAATATTATCCACATCCACGGTCAGGGGGGTTGGACGAGATTGTACTGCGAAGTTTCCTCCGTCAATTA GCTCGCGCCCTCAAATTCTTGCGGCATCGAGACCTCATCCATCGTGATATCAAACCACAGAACCTGCTTCTGAAC CCGGCACCTCCAGAAGAACTGGCAAGAGGGCATCCTCTGGGTGTCCCAATCCTCAAGGTCGCCGACTTTGGTTTC GCAAGATCCCTCCCAAACGCCATGATGGCAGAGACACTCTGCGGGTCGCCCCTGTACATGGCTCCGGAAATCCTT CGCTACGAAAAGTACGACGCCAAGGCCGACCTATGGTCCGTAGGAGCAGTCCTGTACGAAATCGCCACCGGGAGA GCACCCTTCCGAGCCCAGAACCACATCGAGCTATTGAAGAAGATCGAACAATCCAAAGGGCTCAAGTTTCCTGAC GAAGACCCGAAGACGAGTGCAGAGGCGACCCCAGTTCCGGCAGACATCAAGAAGCTCATCCGAGCACTCTTGAAA CGGAATCCGATCGAGAGGGCGAGTTTTGAAGAGTTCTTTAACAGCACTGCGCTCGCCAAATCAAAGTTTCCCCGA CCTCGAGAGCCGGTTGCTGCCGCAAACGCAGAGGAAGACCACAATGGACGGCCCCCGACGCCCGATCATCACAAG GACATCCCCCCAGAAGTACTCGATCCGAACGCGCTGATCCCACCTAGCAAGTTCAATTGGAGGAGACCTACAAAC GGCGACGGGACGGAACCTGCACCAAATGCGAAACCGGTCGAAAAGGCGCGACGAAACAAGGGGCTATCAACAGAA GGTTCGTTTATCCCAGGAGAGACGGAAGAGGATGGAATGCTGCGACGAGAGTATGTGCTCGTCGGAGACACCCGA GCTGTCGAATTCAACCGTGCCGTCGACGAGATCAACACCCTTCCCCGAAAGCCCTTACACGACCGCAAGATCCCT TCCACCCCAGAGGACAGCCCACGACAAGAATACCCTATACCAAATGTCACCAACCCTACAACTCCTCACAACATC ACCTTTCCGCCTCCACCAAACGTCAACGCGCCTCCTTCATTATCGTCGTCACCATCGAGTAACGCATCGAGGGCG GCTGCAAGTGCCTTGAACAGGGCACTGTCATTAGCGACGAAGAAGCTCTTTGGAACTTCAAGACGCCAGCCGTCG ATTTCGTCCCCTGTGCATGAAGTCTCTAGCAACACAAGTCCTCCCTCTTCGCCCAGACGGCCACAGATTATAGCA CTGGACACAGCTGGCGAACGGGATCCACTGGAAGATGAGCTCTTGGCGAACCTGGAAGAACTGGCGCAGAAGACG GACGTGCTCACCCGCTGGGCGGACGAGATGTACGAATATGTGAAAGCTGTTCCCCAGAAACCACTTCCAGATCCA ACGAAGTTCGTCAAGCGCGAGGGGGAGGGGGAGAAACACGCACGAAGGCGGAAGCTGGCCGACATGGAGGCGGAA TACAACGCCGTCACCTGTGTAGCGGTTTATATGCTGCTGATGTCGTTCTCGCAGAAGGGGATCGATAAGCTGAGG AACTTCCAGGAGCATATGAATATGCGGCATCCGGATGGGGATTTCGTGGTCAGCGAAGGCTTCGATGCTGGTGCG TCATTCGATCTACTCATGAAGGTTATTATGGAGAAGTGTGATGTTGACTATGCGATTTGGGTAGCTTTCTCGTGG TTCAAAGATCACTTCATCAAGTGTAATGACCGGGCGGAGCTCGTGAAGACATGGCTACCTGCTCAGTACGATGGA CCTAAAGCTTGGCTGGATCAGCTAGTGTATGATCGTGCTTTGATGCTGAGTCGGACAGCTGCACGAAAGGAGTTG TTGGACCAGGCCGCAGCGCCAGACGAGTGTGAGAAGCTCTACGAGGAATCGTTATGGTGCCTGTACGCCCTTCAA GATGATCTCCTGCAGACAGGTAACCCGTTCATGGAGGAAGATAAGGAAACCATTGGGACATCTGATGATGGCGCA GGGATCAAGCGAACGAAGCTTCGCCTCGTTAGGTGCCGGGCGCGAATGGCCATGAACGACCGCGATCGAATAATC GATGCTCGAGCAGACCAGAACCTCGCCGACGTCGCTCGAATACCTGCTCCATGGGACGTTAAGCCATCGCCTTCA TCCACCTCCTCTCCGACATCTGCCACCGTTCGATCGCCAACATCGCCTGTAAAA |
| Length | 2607 |
Transcript
| Sequence id | CC1G_15592T0 |
|---|---|
| Sequence |
>CC1G_15592T0 ATGCCACCCATACCTGGCCCTTCGTCCTCGAGCAATGATTCGAGCGACGCAAAGCCCTATATCATCGTTTCTGAC ATTGGAAGGGGGAGTTTCGCTACTGTGTACAAAGGATATCATGAGGAAACGCGGTTGCAGGTCGCCATCAAGGCT GTGAAACGGGACAACCTCAGCGCCAGGCTCTTGGACAACCTGCAAAGCGAGATTCAAATCCTAAAGAGCCTGTCC CATCGACACATAACGAAGCTGATTGACATTGTGCGCGCCGAGAAGAACATCTACCTTATCATGGAGTATTGCGCG GGAGGTGACTTGACGAACTATATCAAGAAACGAGGGCGGGTAGAAGGATTGGAATACATTCCTGCACCAGGAGAA CCGCCACAATATTATCCACATCCACGGTCAGGGGGGTTGGACGAGATTGTACTGCGAAGTTTCCTCCGTCAATTA GCTCGCGCCCTCAAATTCTTGCGGCATCGAGACCTCATCCATCGTGATATCAAACCACAGAACCTGCTTCTGAAC CCGGCACCTCCAGAAGAACTGGCAAGAGGGCATCCTCTGGGTGTCCCAATCCTCAAGGTCGCCGACTTTGGTTTC GCAAGATCCCTCCCAAACGCCATGATGGCAGAGACACTCTGCGGGTCGCCCCTGTACATGGCTCCGGAAATCCTT CGCTACGAAAAGTACGACGCCAAGGCCGACCTATGGTCCGTAGGAGCAGTCCTGTACGAAATCGCCACCGGGAGA GCACCCTTCCGAGCCCAGAACCACATCGAGCTATTGAAGAAGATCGAACAATCCAAAGGGCTCAAGTTTCCTGAC GAAGACCCGAAGACGAGTGCAGAGGCGACCCCAGTTCCGGCAGACATCAAGAAGCTCATCCGAGCACTCTTGAAA CGGAATCCGATCGAGAGGGCGAGTTTTGAAGAGTTCTTTAACAGCACTGCGCTCGCCAAATCAAAGTTTCCCCGA CCTCGAGAGCCGGTTGCTGCCGCAAACGCAGAGGAAGACCACAATGGACGGCCCCCGACGCCCGATCATCACAAG GACATCCCCCCAGAAGTACTCGATCCGAACGCGCTGATCCCACCTAGCAAGTTCAATTGGAGGAGACCTACAAAC GGCGACGGGACGGAACCTGCACCAAATGCGAAACCGGTCGAAAAGGCGCGACGAAACAAGGGGCTATCAACAGAA GGTTCGTTTATCCCAGGAGAGACGGAAGAGGATGGAATGCTGCGACGAGAGTATGTGCTCGTCGGAGACACCCGA GCTGTCGAATTCAACCGTGCCGTCGACGAGATCAACACCCTTCCCCGAAAGCCCTTACACGACCGCAAGATCCCT TCCACCCCAGAGGACAGCCCACGACAAGAATACCCTATACCAAATGTCACCAACCCTACAACTCCTCACAACATC ACCTTTCCGCCTCCACCAAACGTCAACGCGCCTCCTTCATTATCGTCGTCACCATCGAGTAACGCATCGAGGGCG GCTGCAAGTGCCTTGAACAGGGCACTGTCATTAGCGACGAAGAAGCTCTTTGGAACTTCAAGACGCCAGCCGTCG ATTTCGTCCCCTGTGCATGAAGTCTCTAGCAACACAAGTCCTCCCTCTTCGCCCAGACGGCCACAGATTATAGCA CTGGACACAGCTGGCGAACGGGATCCACTGGAAGATGAGCTCTTGGCGAACCTGGAAGAACTGGCGCAGAAGACG GACGTGCTCACCCGCTGGGCGGACGAGATGTACGAATATGTGAAAGCTGTTCCCCAGAAACCACTTCCAGATCCA ACGAAGTTCGTCAAGCGCGAGGGGGAGGGGGAGAAACACGCACGAAGGCGGAAGCTGGCCGACATGGAGGCGGAA TACAACGCCGTCACCTGTGTAGCGGTTTATATGCTGCTGATGTCGTTCTCGCAGAAGGGGATCGATAAGCTGAGG AACTTCCAGGAGCATATGAATATGCGGCATCCGGATGGGGATTTCGTGGTCAGCGAAGGCTTCGATGCTGGTGCG TCATTCGATCTACTCATGAAGGTTATTATGGAGAAGTGTGATGTTGACTATGCGATTTGGGTAGCTTTCTCGTGG TTCAAAGATCACTTCATCAAGTGTAATGACCGGGCGGAGCTCGTGAAGACATGGCTACCTGCTCAGTACGATGGA CCTAAAGCTTGGCTGGATCAGCTAGTGTATGATCGTGCTTTGATGCTGAGTCGGACAGCTGCACGAAAGGAGTTG TTGGACCAGGCCGCAGCGCCAGACGAGTGTGAGAAGCTCTACGAGGAATCGTTATGGTGCCTGTACGCCCTTCAA GATGATCTCCTGCAGACAGGTAACCCGTTCATGGAGGAAGATAAGGAAACCATTGGGACATCTGATGATGGCGCA GGGATCAAGCGAACGAAGCTTCGCCTCGTTAGGTGCCGGGCGCGAATGGCCATGAACGACCGCGATCGAATAATC GATGCTCGAGCAGACCAGAACCTCGCCGACGTCGCTCGAATACCTGCTCCATGGGACGTTAAGCCATCGCCTTCA TCCACCTCCTCTCCGACATCTGCCACCGTTCGATCGCCAACATCGCCTGTAAAATGA |
| Length | 2607 |
Gene
| Sequence id | CC1G_15592T0 |
|---|---|
| Sequence |
>CC1G_15592T0 ATGCCACCCATACCTGGCCCTTCGTCCTCGAGCAATGATTCGAGCGACGCAAAGCCCTATATCATCGTTTCTGAC ATTGGAAGGGGGAGTTTCGCTACTGTGTACAAAGGATATCATGAGGTGTGTGCACTCTGTCGTGTAACGTATCGT AAATAACCTTTGTGCCCAGGAAACGCGGTTGCAGGTCGCCATCAAGGCTGTGAAACGGGACAACCTCAGCGCCAG GCTCTTGGACAACCTGCAAAGCGAGATTCAAATCCTAAAGAGCCTGTCCCATCGACACATAACGAAGCTGATTGA CATTGTGGTACGCCAATTGATTGTGACTGACGTCCGTGACTGAGCCTTTTCCCAGCGCGCCGAGAAGAACATCTA CCTTATCATGGAGTATTGCGCGGGAGGTGACTTGACGAACTATATCAAGAAACGAGGGCGGGTAGAAGGATTGGA ATACATTCCTGCACCAGGAGAACCGCCACAATATTATCCACATCCACGGTCAGGGGGGTTGGACGAGATTGTACT GCGAAGTTTCCTCCGTCAATTAGGTACGTCGTAGCGCCCTAACCACCCGTGCCTGTGCTTATCCCTAGCTCAGCT CGCGCCCTCAAATTCTTGCGGCATCGAGACCTCATCCATCGTGATATCAAACCACAGAACCTGCTTCTGAACCCG GCACCTCCAGAAGAACTGGCAAGAGGGCATCCTCTGGGTGTCCCAATCCTCAAGGTCGCCGACTTTGGTTTCGCA AGATCCCTCCCAAACGCCATGATGGCAGAGACACTCTGCGGGTCGCCCCTGTACATGGCTCCGGAAATCCTTCGC TACGAAAAGTACGACGCCAAGGCCGACCTATGGTCCGTAGGAGCAGTCCTGTACGAAATCGCCACCGGGAGAGCA CCCTTCCGAGCCCAGAACCACATCGAGCTATTGAAGAAGATCGAACAATCCAAAGGGCTCAAGTTTCCTGACGAA GACCCGAAGACGAGTGCAGAGGCGACCCCAGTTCCGGCAGACATCAAGAAGCTCATCCGAGCACTCTTGAAACGG AATCCGATCGAGAGGGCGAGTTTTGAAGAGTTCTTTAACAGCACTGCGCTCGCCAAATCAAAGTTTCCCCGACCT CGAGAGCCGGTTGCTGCCGCAAACGCAGAGGAAGACCACAATGGACGGCCCCCGACGCCCGATCATCACAAGGAC ATCCCCCCAGAAGTACTCGATCCGAACGCGCTGATCCCACCTAGCAAGTTCAATTGGAGGAGACCTACAAACGGC GACGGGACGGAACCTGCACCAAATGCGAAACCGTACGTATTTCATATCTGGCCGTGGAGCACTACTGACCCTCCT CTAGGGTCGAAAAGGCGCGACGAAACAAGGGGCTATCAACAGAAGGTTCGTTTATCCCAGGAGAGACGGAAGAGG ATGGAATGCTGCGACGAGAGTATGTGCTCGTCGGAGACACCCGAGCTGTCGAATTCAACCGTGCCGTCGACGAGA TCAACACCCTTCCCCGAAAGCCCTTACACGACCGCAAGATCCCTTCCACCCCAGAGGACAGCCCACGACAAGAAT ACCCTATACCAAATGTCACCAACCCTACAACTCCTCACAACATCACCTTTCCGCCTCCACCAAACGTCAACGCGC CTCCTTCATTATCGTCGTCACCATCGAGTAACGCATCGAGGGCGGCTGCAAGTGCCTTGAACAGGGCACTGTCAT TAGCGACGAAGAAGCTCTTTGGAACTTCAAGACGCCAGCCGTCGATTTCGTCCCCTGTGCATGAAGTCTCTAGCA ACACAAGTCCTCCCTCTTCGCCCAGACGGCCACAGATTATAGCACTGGACACAGCTGGCGAACGGGATCCACTGG AAGATGAGCTCTTGGCGAACCTGGAAGAACTGGCGCAGAAGACGGACGTGCTCACCCGCTGGGCGGACGAGATGT ACGAATATGTGAAAGCTGTTCCCCAGAGTACGTTGCGCTGTTCATGATCGCCATTCTTCCACTCACTTCGTATGC AGAACCACTTCCAGATCCAACGAAGTTCGTCAAGCGCGAGGGGGAGGGGGAGAAACACGCACGAAGGCGGAAGCT GGCCGACATGGAGGCGGAATACAACGCCGTCACCTGTGTAGCGGTTTATATGCTGCTGATGTCGTTCTCGCAGAA GGGGATCGATAAGCTGAGGAACTTCCAGGAGCATATGAATATGCGGCATCCGGATGGGGATTTCGTGGTCAGCGA AGGCTTCGATGCTGGTGCGTCATTCGATCTACTCATGAAGGTTATTATGGAGAAGTGTGATGTTGACTATGCGAT TTGGGTAGCTTTCTCGTGGTTCAAAGATCACTTCATCAAGTGTAATGACCGGGCGGAGCTCGTGAAGACATGGCT ACCTGCTCAGTACGATGGACCTAAAGCTTGGCTGGATCAGCTAGTGTATGATCGTGCTTTGATGCTGGTGAGTAG CGTCGAGGCATTTCGTTATCTCCTGATCAGTTCTGACCTCTACACCAATAGAGTCGGACAGCTGCACGAAAGGAG TTGTTGGACCAGGCCGCAGCGCCAGACGAGTGTGAGAAGCTCTACGAGGAATCGTTATGGTGCCTGTACGCCCTT CAAGATGATCTCCTGCAGACAGGTAACCCGTTCATGGAGGAAGATAAGGAAACCATTGGGACATGTGCGTTATTT TCTTGCTTTTGTATAATCCCAGCTGATGATGGCGCAGGGATCAAGCGAACGAAGCTTCGCCTCGTTAGGTGCCGG GCGCGAATGGCCATGAACGACCGCGATCGAATAATCGATGCTCGAGCAGACCAGAACCTCGCCGACGTCGCTCGA ATACCTGCTCCATGGGACGTTAAGCCATCGCCTTCATCCACCTCCTCTCCGACATCTGCCACCGTTCGATCGCCA ACATCGCCTGTAAAATGA |
| Length | 2943 |